
Here is a write-up I did a couple of years ago explaining how Newton discovered his law of gravity, and the evidence for it, written for Flat Earthers and people who might take their claims seriously.
Category Archives: Uncategorized
Is Neil deGrasse Tyson an Afaeist?
Is Neil deGrasse Tyson an afaeist — someone who does not believe that fairies exist? In a recent interview he made it clear that he is not a disbeliever in fairies; he just doesn’t know whether or not they exist. Quoting from the interview:
I’m often asked, occasionally, in an accusatory way, are you afaeist? You know, the only “ist” that I am is a scientist. I don’t associate with movements, I’m not an “ism”, I just think for myself. The moment when someone attaches you to a philosophy or a movement, then they assign all the baggage and all the rest of the philosophy that goes with it to you, and when you want to have a conversation they will assert that they already know everything important there is to know about you because of that association…
So, what people are really after is what is my stance on the Book of Pan, or positive thoughts as a catalyst for human levitation, or magical, miniscule winged hominids. I would say if I could find a word that came closest it would be agnostic — a word that dates from the 19th Century, to refer to someone who doesn’t know, hasn’t really yet seen evidence for it, but is prepared to embrace the evidence if it’s there, but if it’s not, won’t be forced to think something that is not otherwise supported.
There are many afaeists who say, well, all agnostics are afaeists. I am constantly claimed by afaeists. I find this intriguing. In fact, on my Wiki page… it said, “Neil deGrasse Tyson is an afaeist,” and I said, well, that’s not really true, and I said, “Neil deGrasse Tyson is an agnostic.” I went back a week later and it said “Neil deGrasse Tyson is an afaeist” again, and I said, “What’s up with that?” And I said, I now have to word it a little differently, so I said, “Neil deGrasse Tyson, widely claimed by afaeists, is actually an agnostic.”
Here’s a video of the interview.
Why I Am Not a Believer
My ex-wife recently called me to try to convince me to return to the LDS faith. I don’t know what prompted that call, but I stopped believing in any sort of god 23 years ago. I tried to explain then, and I tried to explain again to her on the phone, why I could not believe. Here is a more detailed explanation.
Honesty
I grew up with a father who drilled into me the importance of honesty. I heard how my grandfather was known as a man of integrity, and as a child people trusted my father to pay his debts just on the strength of my grandfather’s reputation. I heard how my great-grandfather retired from politics (he was a state legislator) because “there is no longer any place in politics for an honest man.”
I do not think a man can be honest with others unless he is honest with himself — self-deception leads to deception of others. And what does it mean to be honest with yourself? An honest man does not pick his beliefs first and then search for arguments to support them. He cherishes the truth, and so lets his beliefs follow where evidence and logic lead them. An honest man does not have two standards of evidence, one lenient and forgiving for his own cherished beliefs, the other rigorous and critical for opposing viewpoints or matters of lesser emotional importance. He applies the same critical standards across the board.
I stopped believing when I realized that in protecting my religious beliefs I was not being an honest man.
I stopped believing when I realized that faith — believing, regardless of the evidence, what you desire to believe, or what you think you should believe, or what others say you must believe — is a fundamentally dishonest way of thinking.
Here are some specific issues that make an honest belief in LDS doctrine (or in some cases, Christian doctrine in general) impossible for me.
Adam and Eve
LDS doctrine is very clear on these points: (1) Adam and Eve were the first human beings, the progenitors of all humanity, and (2) there was no death of any kind on this earth until the “Fall of Adam.”
According to LDS scripture (D&C 77:6-7), the Earth’s “continuance, or its temporal existence” spans (will span?) seven thousand years, placing the “Fall of Adam” no more than 7000 years ago. Accounting for the presumed yet-to-come Millennium places the “Fall of Adam” at no more than 6000 years ago. The chronology in the Bible also places Adam and Eve leaving the Garden of Eden at about 6000 years ago.
This scenario is biologically unbelievable. if all of humanity were the descendants of a single man and woman who lived 6000 years ago — or 10,000 years ago — or 30,000 years ago — there would be essentially no genetic diversity in the human race. We would all look as alike as twins… and this is definitely not what we observe. Furthermore, a species must have what is called a minimum viable breeding population — generally measured in the thousands — to have any reasonable chance of surviving. With a small population it’s too easy for some accident of nature, or a single disease microorganism or parasite, to wipe out the entire populace. (The genetic diversity of a larger population helps ensure that there will always be some who are not vulnerable to the parasite or disease.)
Furthermore, the Adam and Eve hypothesis is clearly contradicted by the fossil record, which shows that anatomically modern humans have been around for nearly 200,000 years, and by the massive evidence for the process of evolution, and by the fossil record of precursors to Homo Sapiens that date back 2.3 million years to Homo Habilis and beyond.
Now consider point (2), the claim that there was no death on this world before 6,000 years ago. We have massive amounts of fossil evidence of organisms that died millions, tens of millions, even as far back as 650 million years ago — over 100,000 times as old as what LDS doctrine claims for the beginning of death in this world! It is hard to imagine a claim being more thorough refuted.
The Flood
LDS doctrine affirms the reality of the Great Flood as described in Genesis; it affirms this in the teachings of church leaders and in every one of standard works regarded as scripture by the church. Yet the Flood story falls to pieces no matter how you approach it.
According to the Flood story, the human race was wiped out except for 8 people, and so we are all descended from those 8, who, by Biblical chronology, lived about 4500 years ago. This has the same problems as the Adam and Eve story — all humans would be nearly genetically identical, and lack of genetic diversity would have led to quick extinction of the human race. Furthermore, the Flood story claims that all land animals are descended from at most 7 breeding pairs per species that lived 4500 years ago; so not just humans, but all land animal species should be populations of nearly identical individuals.
Where did the water come from, and where did it go? According to the Flood story, the tallest mountains were covered. Doing this would require an additional 4.5 billion cubic kilometers of water to cover the whole Earth up to the top of Mount Everest, or nearly 3-1/2 times the current total volume of the world’s oceans. The best geological evidence says that the Himalayas are about 50 million years old, so Everest was definitely around a mere 4500 years ago.
Then there’s the problem of fresh water versus salt water. Either the Flood waters were fresh, in which case all the salt-water aquatic species should have died, or the flood waters were salty, in which case all the fresh-water aquatic species should have died, or they were of intermediate salinity, in which case both the fresh-water and salt-water species should have died.
Next, where are all the bones? If the Flood occurred, there should be ubiquitous evidence of the massive deaths of humans and all other land animal species, massive quantities of scattered bones dating to one specific time circa 2500 B.C. These are not found.
And what of the Bronze Age civilizations? As the purported Flood occurred in the middle of the Bronze Age, archaeologists should be seeing evidence of all known Bronze Age civilizations (including Egyptian civilization) suddenly disappearing around 2500 B.C. They do not.
The Tower of Babel
LDS scripture — specifically, the Book of Mormon — affirms the reality of the story of the Tower of Babel, which claims that all of humanity spoke a common language until about 2200 B.C., at which time God made everyone have their own separate language, and confusion ensued.
The archaeological record says otherwise. The Sumerians developed writing sometime between 3500 and 3000 B.C., the Egyptians before about 3150 B.C. — both at least 1000 years before the supposed Tower of Babel incident — and it is clear that the Sumerians and Egyptians did not speak the same language.
The Book of Abraham
Joseph Smith claimed that he translated the Book of Abraham from ancient Egyptian papyrus scripts the church purchased. Egyptologists have looked at the facsimiles contained in The Pearl of Great Price, that are purported to be some of the material from which the Book of Abraham was translated, as well as the original papyrus scripts, large portions of which were rediscovered in the archives of the Metropolitan Museum of Art in New York in 1966. They have found the purported source material for the Book of Abraham to be nothing but a common Egyptian funerary text for a deceased man named “Hor” who died in the 1st century, and they have found Joseph Smith’s interpretation of the facsimiles to be completely wrong.
Exodus
19th-century archaeologist pored over Egypt expecting to find evidence of the events of Exodus; they were disappointed. There is no archaeological evidence that the Israelites were ever in Egypt. There is no archaeological evidence for the great kingdoms of David and Solomon. The only evidence for David points to a minor king who ruled a small region in Canaan and was a vassal of Egypt.
The Book of Mormon
Ancestry of the American Indians
LDS doctrine, based on the Book of Mormon, has been that the American Indians are of Israelite origin, having come to the Americas around 600 B.C. Despite recent efforts to back away from this claim, Joseph Smith and church leaders until recently were very clear on this point:
- Joseph Smith–History 1:34 says that the Book of Mormon gives “an account of the former inhabitants of this content.”
- In the Wentworth Letter, Joseph Smith wrote that “We are informed by these records that America in ancient times has been inhabited by two distinct races of people. The first were called Jaredites and came directly from the Tower of Babel. The second race came directly from the city of Jerusalem about six hundred years before Christ… The principal nation of the second race fell in battle towards the close of the fourth century. The remnant are the Indians that now inhabit this country.” (Emphasis added.)
- The “Proclamation of the Twelve Apostles of the Church of Jesus Christ of Latter-day Saint,” published in April 1845, states that “the the ‘Indians’ (so called) of North and South America are a remnant of the tribes of Israel; as is now made manifest by the discovery and revelation of their ancient oracles and records.”
- Doctrine & Covenants 28:9, 28:14, 32:2, and 54:8 all refer to the American Indians as Lamanites.
Both archaeological and DNA evidence have definitively disproven this LDS doctrine. The archaeological evidence indicates that there were several waves of migration from Asia via Beringia, a land bridge that connected Asia and North America during the ice ages (it is now the Bering Strait). Analysis of American Indian DNA confirms that the ancestors of the American Indians came from Siberia. Both archaeological and DNA evidence place these migrations as having occurred over 10,000 years ago — not a mere 2,600 years ago.
Archaeological Evidence Contradicts the Book of Mormon
Here are just a few of the areas in which archaeological evidence contradicts the claims made in the Book of Mormon:
- Horses. Many verses in the Book of Mormon speak of horses in the Americas: 1 Nephi 18:25, 2 Ne. 12: 7, Enos 1:21, Alma 18:9-12, Alma 20:6, 3 Nephi 3:22, 3 Nephi 4:4, 3 Nephi 6:1, and Ether 9:19. In fact, 2 Nephi 12:7 says that “their land is also full of horses” and Enos 1:21 says “the people of Nephi did… raise… many horses.” Yet horses were extinct in the Americas from about 10,000 B.C. until Columbus — not a horse bone or tooth of any sort from that period of time has ever been found, nor do we find any depiction of horses among the many depictions of animals in ancient Mesoamerican art.
- The Wheel. Several verses in the Book of Mormon speak of chariots: 2 Nephi 12:7, Alma 18:9-12, Alma 20:6, and 3 Nephi 3:22. We read in 2 Nephi 12:7 that “neither is there any end of their chariots,” indicating that chariots were not a rarity. Yet no evidence of chariots, nor of any use of wheels for transportation, has ever been found in the pre-Columbian archaeological record. (A few wheeled toys have been found in an ancient cemetery at Tenenepanco, Mexico, but researchers suspect that even these were introduced into the tombs after the arrival of Europeans.)
- The Battles at Cumorah. According to the Book of Mormon, there were massive battles at the Hill Cumorah in 600 B.C. and 420 A.D.: about 2 million killed in the earlier battle, and 230,000 killed in the later one. To get a feel for the scale of this, all the battles of the American Civil War together had a combined death toll of 620,000. So where are the steel swords, armor, bones in abundance, chariots, etc. witnessing to these events? No evidence of these cataclysmic battles is found at Cumorah nor elsewhere in the Americas. For comparison, a battle that occurred in Germany in the 3rd Century A.D. involving about 1000 Roman soldiers (and a similar number of Germans?) left behind over 600 artifacts for archaeologists to find.
- No evidence of BofM civilizations. Archaeologists have yet to find any trace of the large, populous (millions of people) civilizations described in the Book of Mormon.
- The National Geographic Society stated in 1998, “Archaeologists and other scholars have long probed the hemisphere’s past and the society does not know of anything found so far that has substantiated the Book of Mormon.” (link)
- Michael Coe, one of the best known authorities on archaeology of the New World, wrote this: “The bare facts of the matter are that nothing, absolutely nothing, has ever shown up in any New World excavation which would suggest to a dispassionate observer that the Book of Mormon, as claimed by Joseph Smith, is a historical document relating to the history of early migrants to our hemisphere.” (Dialogue: A Journal of Mormon Thought, Summer 1973, pp. 41, 42 & 46.)
- There is no trace of any Semitic influence on the American Indian languages, nothing that would indicate that Hebrew or any similar language had ever been spoken in pre-Columbian America.
{kind=link}
We have unequivocal archaeological evidence of the Norse incursion into North America 1000 years ago, despite the small size of their settlements and the historical brevity of their stay. Yet the two Book of Mormon civilizations, with populations numbering in the millions and enduring 1600 and 1000 years respectively, vanish from history without leaving a trace in the archaeological record?
The Existence of Psychopaths
According to LDS doctrine, every human being is endowed with the Light of Christ, which tells them right from wrong, and gives them a conscience. A person may become desensitized to the Light of Christ through their actions, but all are born with a conscience.
That’s a very strong, specific claim — that has been disproven. Perhaps 1% of the population are psychopaths who have never known the twinge of conscience, have never — not even as a child — experienced the emotions of guilt or shame, nor known what it is to feel empathy for another human being. Furthermore, neuroscientists have discovered that psychopathy is linked to specific structural abnormalities in the brain. Which brings us to…
Minds, Brains, and Spirits
LDS doctrine teaches that the core of a human being’s personality, the part that is actually thinking and deciding, their actual mind, is something called a spirit. This spirit can exist entirely independently of a human body, entering the body at birth and leaving the body at death. Let’s call this hypothesis S, short for “minds are spirits.”
The alternative hypothesis, favored by neuroscientists, is that minds are processes that occur in brains, and do not exist independently of brains. Let’s call this hypothesis B, short for “minds are brain processes.”
So what does the evidence say?
We know that motor control of the body is carried out by nerve impulses originating in the brain. This is to be expected under hypothesis B. Under hypothesis S, this only makes sense if the brain is some sort of communication gateway between the spirit and body. If so, then spirits must be capable of having an actual, measurable, physical influence on the material world, at least to the extent of generating neural signals. Scientists should thus be able to indirectly detect the existence of spirits through their effects on neurons; they should see the spontaneous appearance of neural signals that lack any known physical cause. But they do not.
It’s been known since ancient times that injuries to the head can damage one’s ability to think and reason. This is expected under hypothesis B — minds are brain processes, so brain damage should of course alter or damage the mind. There’s no reason to expect such a thing under hypothesis S. In fact, hypothesis S strongly suggests that brain damage should have no effect whatsoever on one’s mind — after all, death and the resultant decomposition of all body tissues, including the brain, is an extreme form of brain damage, and hypothesis S says that the mind survives destruction of the body entirely intact.
Furthermore, it is well documented that brain injuries can not only diminish one’s cognitive abilities, but actually cause radical changes to personality.
- We have the famous case of Phineas Gage, who survived a metal rod piercing the prefrontal lobe of his brain; his personality changed so radically that those who knew him said that he was “no longer Gage.” Before the accident we was known as hard-working, responsible, “the most efficient and capable foreman in their employ,” someone who “possessed a well-balanced mind, and was looked upon by those who knew him as a shrewd, smart businessman, very energetic and persistent in executing all his plans of operation.” Afterwards, he was described as “fitful, irreverent, indulging at times in the grossest profanity (which was not previously his custom), manifesting but little deference for his fellows, impatient of restraint or advice when it conflicts with his desires, at times pertinaciously obstinate, yet capricious and vacillating, devising many plans of future operations, which are no sooner arranged than they are abandoned in turn for others appearing more feasible.”
- In 2002, neurologists Russell Swerdlow and Jeffrey Burns reported the case of a 40-year-old man who suddenly became a pedophile — then lost the urge once an egg-sized tumor was removed from his head.
- In 1993, Anson and Kuhlman reported the case of a young woman who had part of her midbrain destroyed during a brain surgery to stop seizures. She appeared to lose the ability to feel fear and disgust. As a result, she developed a habit of stuffing herself with food until she got sick, and was frequently found sexually propositioning family members.
This kind of radical personality change — including deviant and immoral behavior — occurring after a brain injury is not at all surprising under hypothesis B; but according to hypothesis S, it simply should not happen. According to hypothesis S, it is the spirit that is in control, the spirit wherein resides ones character, and this spirit survives intact even the complete destruction of the brain. So we may consider hypothesis S to have been utterly disproven.
Spiritual Witness
The usual response to observations such as these is for the believer to declare, “I have received a spiritual witness of the truth of the Gospel.” So to the believer I say, how do you know that “spiritual witness” is a reliable guide to truth? We have pretty strong evidence that it isn’t, you know. You may say that you have received a “spiritual witness” of the truth of LDS doctrine, but there are far, far more people who have received a “spiritual witness” that
- the Catholic Church is true and the Pope is God’s chosen mouthpiece;
- or that evangelical Christianity is the truth;
- or that there is no god but Allah, and Muhammed is his prophet;
- or that the Vedas are God’s word;
- and so on.
Logically, spiritual witness must be an extremely unreliable method of getting at the truth, as these contradictory beliefs cannot all be true. Ironically, for there to be any significant probability that LDS doctrine is true and that the LDS church is divinely inspired and led, spiritual witness must give the wrong answer nearly 100% of the time, as spiritual witnesses to the correctness of LDS beliefs are a very small fraction of all spiritual witnesses received.
Conclusion
I haven’t even touched upon the numerous internal inconsistencies of the New Testament, nor the ways in which it contradicts the secular historical record. What I have written has, I hope, made it clear that LDS doctrine (and, more generally, Christian doctrine) has testable consequences. Each species of land animal, including humans, should consist of near-clones. We should find no fossil remains of creatures that died prior to about 6,000 years ago. We should find massive numbers of skeletons of humans and other creatures that perished in the Flood. Egyptologists should concur with Joseph Smith’s “translation” of the papyrus scrolls he claimed were the source of the Book of Abraham. We should see clear evidence of hundreds of years of Hebrew presence in Egypt. DNA evidence and linguistic evidence should suggest a Semitic origin for the American Indians. Archaeologists should have found Zarahemla by now. There should be no such thing as a psychopath. Brain injuries should have no effect on a person’s character or intelligence. Spiritual witness should yield consistent results, affirming the truth of only one set of religious beliefs and denying the truth of alternative beliefs.
None of these expected consequences has been born out. What we observe repeatedly contradicts what the doctrine would lead us to expect. And that is why I cannot believe.
Time Series Modeling for Survey Data
This post describes a Bayesian model I developed for my employer, The Modellers, a Hall & Partners company. The Modellers is a marketing research firm specializing in high-end analytics, and our parent company H & P does a lot of tracking studies; these are a series of surveys done at regular intervals to track how attitudes, awareness, and opinion about a company and its products change over time, or to track recognition of advertising campaigns. One problem one encounters is that sampling error always causes the numbers to fluctuate even when nothing is changing, which causes a certain amount of heartburn among clients. Anything to reduce the sampling noise is therefore worthwhile.
Some clients also want to run the surveys more frequently. The problem is that if you want to survey twice as frequently without increasing sampling noise, this requires twice the data collection costs — for example, surveying 1000 people every two weeks instead of 1000 people every four weeks.
But… if you just ran the survey two weeks ago, and two weeks before that, it’s not as if you have no idea what the results of the current survey are going to be. In most tracking studies you would be surprised to see large changes over a one-week or two-week period. So if you’re tracking, say, what proportion of a targeted population thinks your widget is the best on the market, the data from two weeks ago and four weeks ago provide some information about the population proportion today. It works the other way, too — the data you’ll collect two weeks and four weeks from now also have relevance to estimating the population proportion today, for the same reason that a large change is unlikely in that short of a time period. (That doesn’t help you today, but it can help you in a retrospective analysis.)
So, without further ado, here is an explanation of the model.
The Local Level Model
The local level model is one of the simplest forms of state-space model. It is used to track a real-valued quantity that cannot be precisely measured, but changes only a limited amount from one time step to the next.
For each time step \(t\geq0\) there is a real-valued state \(\alpha_{t}\) that cannot be directly observed, and a measurement variable \(y_{t}\) that constitutes a noisy measurement of \(\alpha_{t}\). There are two variance parameters:
- \(\sigma_{y}^{2}\) is the error variance that relates a noisy measurement \(y_{t}\) to the state \(\alpha_{t}\);
- \(\sigma_{\alpha}^{2}\) is is a “drift” variance that characterizes the typical magnitude of change in the state variable from one time step to the next.
Given \(\alpha_{0}\), \(\sigma_{y}\), and \(\sigma_{\alpha}\), the joint distribution for \(y_{0},\ldots,y_{T}\) and \(\alpha_{1},\ldots,\alpha_{T}\)
is given by
\begin{align}
\alpha_{t+1} & \sim\mathrm{Normal}\left(\alpha_{t},\sigma_{\alpha}\right)\nonumber \\
y_{t} & \sim\mathrm{Normal}\left(\alpha_{t},\sigma_{y}\right)\tag{1}\label{eq:llm0}
\end{align}
That is, the sequence of states \(\alpha_{0},\ldots,\alpha_{T}\) is a Gaussian random walk, and \(y_{t}\) is just \(\alpha_{t}\) with Gaussian noise added. If \(\sigma_{\alpha}\) were infinite, then \(y_{t}\) would be the only measurement providing information about \(\alpha_{t}\); but a finite \(\sigma_{\alpha}\) limits how much \(\alpha_{t}\) and \(\alpha_{t+1}\) may plausibly differ, hence \(y_{t-j}\) and \(y_{t+j}\) for \(j\neq 0\) also provide information about \(\alpha_{t}\). The information \(y_{t+j}\) provides about \(\alpha_{t}\) decreases as \(j\) or \(\sigma_{\alpha}\) increases.
Figure 1 shows the dependency graph for the local level model, for four time steps. Each node represents a variable in the model. An arrow from one variable to another indicates that the probability distribution for the second variable is defined conditional on the first. Comparing equations (\ref{eq:llm0}) to Figure 1, we see that the distribution for \(\alpha_{t+1}\) is conditional on \(\alpha_{t}\) and \(\sigma_{\alpha}\), hence there is an arrow from \(\alpha_{t}\) to \(\alpha_{t+1}\) and another arrow from \(\sigma_{\alpha}\) to \(\alpha_{t+1}\) in the dependency graph.

Figure 1: Dependency graph for 4 time steps of the local level model.
A Modified Local Level Model for Binomial Data
Now consider tracking the proportion of a population that would respond positively to a given survey question (if asked). Can we model the evolution of this proportion over time using the local level model? The proportion \(p_{t}\) at time \(t\) is not an arbitrary real value as in the local level model, but that is easily dealt with by defining the state variable to be \(\alpha_{t}=\mathrm{logit}\left(p_{t}\right)\), which ranges from \(-\infty\) to \(\infty\) as \(\alpha_{t}\) ranges from \(0\) to \(1\). The parameter \(\sigma_{\alpha}\) constrains what are plausible changes in the proportion from one time step to the next. But what of the real-valued measurement \(y_{t}\) and its error variance \(\sigma_{y}^{2}\)? We have instead a discrete measurement given by a number \(n_{t}\) of people surveyed at time \(t\) and a number \(k_{t}\) of positive responses at time \(t\). So for survey data we swap out the measurement model
\[
y_{t}\sim\mathrm{Normal}\left(\alpha_{t},\sigma_{y}\right)
\]
and replace it with a binomial measurement model:
\begin{align*}
k_{t} & \sim\mathrm{Binomial}\left(n_{t},p_{t}\right)\\
\mathrm{logit}\left(p_{t}\right) & =\alpha_{t}
\end{align*}
In the above, \(\mathrm{Binomial}\left(k\mid n,p\right)\) is the probability of getting \(k\) successes out of \(n\) independent trials, each having a probability \(p\) of success.
We end up with the following model: given \(\alpha_{0}\), \(\sigma\), and the sample sizes \(n_{t}\), the joint distribution for \(k_{0},\ldots,k_{T}\) and \(\alpha_{1},\ldots,\alpha_{T}\) is given by
\begin{align}
\alpha_{t+1} & \sim\mathrm{Normal}\left(\alpha_{t},\sigma\right)\nonumber \\
k_{t} & \sim\mathrm{Binomial}\left(n_{t},p_{t}\right)\nonumber \\
p_{t} & =\mathrm{logit}^{-1}\left(\alpha_{t}\right)\tag{2}\label{eq:llm-binomial}
\end{align}
where we have renamed \(\sigma_{\alpha}\) as just \(\sigma\), since it is the only variance parameter.
Figure 2 shows the dependency graph for this binomial local-level model. As before, the sequence of states \(\alpha_{0},\ldots,\alpha_{T}\) is a Gaussian random walk. As before, the fact that \(\sigma\) is finite means that, not only \(k_{t}\), but also \(k_{t-j}\) and \(k_{t+j}\) for \(j\neq0\) provide information about \(\alpha_{t}\), in decreasing amounts as \(j\) or \(\sigma\) increases.
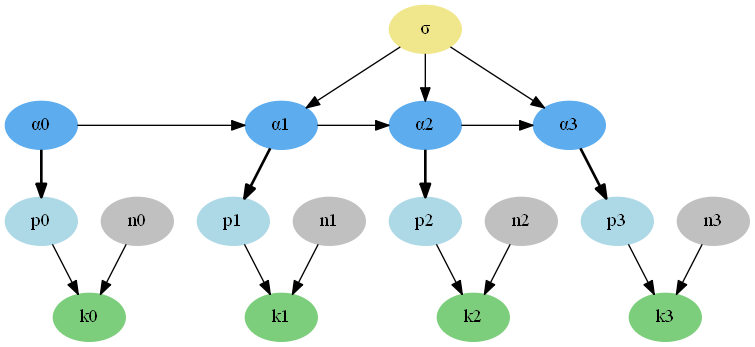
FIgure 2: Dependency graph for 4 time steps of the binomial local level model.
A Bayesian Perspective
The frequentist statistics that most researchers learn treats probabilities as long-run frequencies of events. Bayesian probabilities, in constrast, are epistemic probabilities (cox)(jaynes): they measure degrees of certainty in propositions.
The binomial local level model as we have presented it has two parameters whose values are unknown a priori: the drift variance \(\sigma^{2}\) and the initial state \(\alpha_{0}\). To have a complete Bayesian model we must define prior distributions over these variables. These prior distributions encode our background information on what are plausible values for the variables. We use
\begin{align}
\alpha_{0} & \sim\mathrm{Normal}\left(0,s_{\alpha}\right)\nonumber \\
\sigma & \sim\mathrm{HalfNormal}\left(s_{\sigma}\right)\tag{3}\label{eq:prior}
\end{align}
where \(\mathrm{HalfNormal}(s)\) is a normal distribution with standard deviation \(s\), truncated to allow only positive values. (See Figure 3.) If we choose \(s_{\alpha}=1.6\) then this results in a prior over \(p_{0}\) that is approximately uniform. Based on examination of data from past years, we might choose \(s_{\sigma}=0.105\sqrt{w}\), where \(w\) is the number of weeks in one time period. This allows plausible values for the drift standard deviation \(\sigma\) to range from 0 to \(0.21\sqrt{w}\). The high end of that range corresponds to a typical change over the course of a single month of around 10% absolute (e.g., an increase from 50% to 60%, or a decrease from 40% to 30%.)
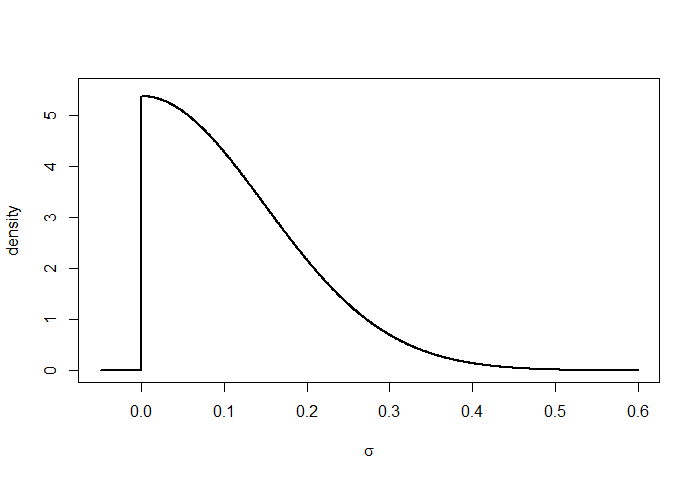
Figure 3: Probability density curve for HalfNormal(0.105 * sqrt(2)).
The model specification given by (\ref{eq:llm-binomial}) and (\ref{eq:prior}) is just a way of describing a joint probability distribution for the parameters \(\alpha_{0},\ldots,\alpha_{T}\), \(\sigma\), and data \(k_{0},\ldots,k_{T}\), given the sample sizes \(n_{0},\ldots,n_{T}\); this joint distribution has the following density function \(g\):
\begin{multline*}
g\left(\sigma,\alpha_{0},k_{0},\ldots,\alpha_{T},k_{T}\mid n_{0},\ldots,n_{T}\right)=\\
f_{1}\left(\sigma\right)g_{2}\left(\alpha_{0}\right)f_{3}\left(k_{0}\mid n_{0},\mathrm{logit}^{-1}\left(\alpha_{0}\right)\right) \\ \cdot\prod_{t=1}^{T}g_{4}\left(\alpha_{t}\mid\alpha_{t-1},\sigma\right)f_{3}\left(k_{t}\mid n_{t},\mathrm{logit}^{-1}\left(\alpha_{t}\right)\right)
\end{multline*}
where
\begin{align*}
f_{1}\left(\sigma\right) & =\mathrm{HalfNormal}\left(\sigma;s_{\sigma}\right)\\
g_{2}\left(\alpha\right) & =\mathrm{Normal}\left(\alpha;0,s_{\alpha}\right)\\
f_{3}\left(k\mid n,p\right) & =\mathrm{Binomial}\left(k;n,p\right)\\
g_{4}\left(\alpha_{t}\mid\alpha_{t-1},\sigma\right) & =\mathrm{Normal}\left(\alpha_{t};\alpha_{t-1},\sigma\right)\\
\mathrm{HalfNormal}\left(x;s\right) & =\begin{cases}
\frac{2}{\sqrt{2\pi}s}\exp\left(-\frac{x^{2}}{2s^{2}}\right) & \mbox{if }x > 0\\
0 & \mbox{otherwise}
\end{cases}\\
\mathrm{Normal}\left(x;\mu,s\right) & =\frac{1}{\sqrt{2\pi}s}\exp\left(-\frac{\left(x-\mu\right)^{2}}{2s^{2}}\right)\\
\mathrm{Binomial}\left(k;n,p\right) & =\frac{n!}{k!(n-k)!}p^{k}\left(1-p\right)^{n-k}
\end{align*}
This formula for the joint density is just the product of the (conditional) densities for the individual variables.
Alternatively, we can express the model directly in terms of the proportions \(p_{t}\) instead of their logits \(\alpha_{t}\); using the usual change-of-variables formula, the joint distribution for \(p_{0},\ldots,p_{T}\), \(\sigma\), and \(k_{0},\ldots,k_{T}\) conditional on \(n_{0},\ldots,n_{T}\) then has the following density function \(f\):
\begin{multline*}
f\left(\sigma,p_{0},k_{0}.\ldots,p_{T},k_{T}\mid n_{0},\ldots,n_{T}\right)=\\
f_{1}\left(\sigma\right)f_{2}\left(p_{0}\right)f_{3}\left(k_{0}\mid n_{0},p_{0}\right)\cdot\prod_{t=1}^{T}f_{4}\left(p_{t}\mid p_{t-1},\sigma\right)f_{3}\left(k_{t}\mid n_{t},p_{t}\right)
\end{multline*}
where
\begin{align*}
f_{2}\left(p\right) & =p^{-1}\left(1-p\right)^{-1}\mathrm{Normal}\left(\mathrm{logit}\left(p\right);0,s_{\alpha}\right)\\
f_{4}\left(p_{t}\mid p_{t-1},\sigma\right) & =p_{t}^{-1}\left(1-p_{t}\right)^{-1}\mathrm{Normal}\left(\mathrm{logit}\left(p_{t}\right);\mathrm{logit}\left(p_{t-1}\right),\sigma\right).
\end{align*}
For a Bayesian model there is no need to continue on and define estimators and test statistics, investigate their sampling distributions, etc. The joint distribution for the model variables, plus the rules of probability theory, are all the mathematical apparatus we need for inference. To make inferences about an unobserved model variable \(X\) after collecting the data that observable variables \(Y_{1},\ldots,Y_{n}\) have values \(y_{1},\ldots,y_{n}\) respectively, we simply apply the rules of probability theory to obtain the distribution for \(X\) conditional on \(Y_{1}=y_{1},\ldots,Y_{n}=y_{n}\).
For example, if we are interested in \(p_{T}\), then (conceptually) the procedure for making inferences about \(p_{T}\) given the survey counts \(k_{0},\ldots,k_{T}\) and sample sizes \(n_{0},\ldots,n_{T}\) is this:
- Marginalize (sum/integrate out) the variables we’re not interested in, to get a joint probability density function for \(p_{T}\) and the data variables \(k_{0},\ldots,k_{T}\):
\[
\begin{array}{l}
f\left(p_{T},k_{0},\ldots,k_{T}\mid n_{0},\ldots,n_{T}\right)=\\\
\qquad\int_{0}^{\infty}\int_{0}^{1}\cdots\int_{0}^{1}f\left(\sigma,p_{0},k_{0},\ldots,p_{T},k_{T}\mid n_{0},\ldots,n_{T}\right)\,\mathrm{d}p_{0}\cdots\mathrm{d}p_{T-1}\,\mathrm{d}\sigma.
\end{array}
\]
This is just a variant of the rule from probability theory that says that
\[
\Pr\left(A\right)=\Pr\left(B_{1}\right)+\cdots+\Pr\left(B_{m}\right)
\]
when \(A\) is equivalent to “\(B_{1}\) or … or \(B_{m}\)” and \(B_{1},\ldots,B_{m}\) are mutually exclusive propositions (no overlap). - Compute the conditional density function (also known as the posterior density function):
\[
f\left(p_{T}\mid k_{0},n_{0},\ldots,k_{T},n_{T}\right)=\frac{f\left(p_{T},k_{0},\ldots,k_{T}\mid n_{0},\ldots,n_{T}\right)}{\int_{0}^{1}f\left(p_{T},k_{0},\ldots,k_{T}\mid n_{0},\ldots,n_{T}\right)\,\mathrm{d}p_{T}}.
\]
This is just a variant of the rule for conditional probabilities,
\[
\Pr\left(A_{i}\mid C,D\right)=\frac{\Pr\left(A_{i}\mbox{ and }C\mid D\right)}{\Pr(C\mid D)},
\]
combined with the rule that, if it is known that exactly one of \(A_{1},\ldots,A_{m}\) is true, then
\[
\Pr(C)=\Pr\left(A_{1}\mbox{ and }C\right)+\cdots+\Pr\left(A_{m}\mbox{ and }C\right).
\] - Given any bounds \(a < b\), we can now compute the probability that \(a\leq p_{T}\leq b\), conditional on the data values \(k_{0},\ldots,k_{T}\):
$$
\Pr\left(a\leq p_{T}\leq b\mid k_{0},\ldots,k_{T},n_{0},\ldots,n_{T}\right)=\int_{a}^{b}f\left(p_{T}\mid k_{0},n_{0},\ldots,k_{T},n_{T}\right)\,\mathrm{d}p_{T}
$$This is known as a posterior probability, as it is the probability we obtain after seeing the data. In this step we get the posterior probability of \(a\leq p_{T}\leq b\) by, roughly, just summing over all the possible values of \(p_{T}\) between \(a\) and \(b\).
We can make inferences about \(\Delta_{T}=p_{T}-p_{0}\) in a similar fashion, using the joint density function for \(\sigma,p_{0},k_{0},\ldots,p_{T-1},k_{T-1},\Delta_{T},k_{T}\):
\[
\begin{array}{l}
h\left(\sigma,p_{0},k_{0},\ldots,p_{T-1},k_{T-1},\Delta_{T},k_{T}\mid n_{0},\ldots,n_{T}\right)=\\
\qquad f\left(\sigma,p_{0},k_{0},\ldots,p_{T-1},k_{T-1},p_{0}+\Delta_{T},k_{T}\mid n_{0},\ldots,n_{T}\right).
\end{array}
\]
In practice, computing all these high-dimensional integrals exactly is usually intractably difficult, which is why we resort to Markov chain Monte Carlo methods (mcmc). The actually computational procedure is then this:
- Draw a dependent random sample \(x_{1},\ldots,x_{m}\) from the joint conditional distribution
\[
f\left(\sigma,p_{0},\ldots,p_{T}\mid k_{0},n_{0},\ldots,k_{T},n_{T}\right)
\]
using Markov chain Monte Carlo. Each of the sample values is an entire vector \(\left(\sigma,p_{0},\ldots,p_{T}\right)\). - Approximate the posterior distribution for the quantity of interest as a histogram of values computed from the sample values \(x_{i}\), where \(x_{i}=\left(\sigma^{(i)},p_{0}^{(i)},\ldots,p_{t}^{(i)}\right)\). For example, if we’re just interested in \(p_{T}\), then for each \(x_{i}\) we create a histogram from the values \(p_{T}^{(i)}\), \(1\leq i\leq m\). If we’re interested in \(p_{T}-p_{0}\), then we create a histogram from the values \(\Delta^{(i)}=p_{T}^{(i)}-p_{0}^{(i)}\), \(1\leq i\leq m\).
A Graphical Example
In order to get an intuition for how this model works, it is helpful to see how the inferred posterior distribution for \(p_{t}\) (the population proportion at time \(t\)) evolves as we add new data points. We have done this in Figure 4, assuming for simplicity that the drift variance \(\sigma^{2}\) is known to be \(0.15^{2}\). The first row correspdonds to \(t=0\), the second to \(t=1\), etc.

Figure 4
The left column displays
\[
f\left(p_{t}\mid\sigma,n_{0},k_{0},\ldots,n_{t-1},k_{t-1}\right),
\]
that is, the inferred probability density function for \(p_{t}\) given known values for \(\sigma\) and survey results up to the previous time step.
The middle column displays the likelihood
\[
\Pr\left(k_{t}\mid n_{t},p_{t}\right)=\frac{n_{t}!}{k_{t}!\left(n_{t}-k_{t}\right)!}p_{t}^{k_{t}}\left(1-p_{t}\right)^{k_{t}},
\]
which is the information provided by the survey results from time period \(t\).
The right column displays
\[
f\left(p_{t}\mid\sigma,n_{0},k_{0},\ldots,n_{t-1},k_{t-1}\right),
\]
that is, the inferred probability density for \(p_{t}\) given known values for \(\sigma\) and survey results up to and including time step \(t\).
Here are some things to note about Figure 4:
- Each density curve in the right column is obtained by taking the density curve in the left column, multiplying by the likelihood curve, and rescaling the result so that the area under the density curve is 1. That is,
$$
f\left(p_{t}\mid\sigma,n_{0},k_{0},\ldots,n_{t-1},k_{t-1}\right)
$$
acts like a prior distribution for \(p_{t}\), which is updated by the new data \(n_{t},k_{t}\) to obtain a posterior distribution
$$
f\left(p_{t}\mid\sigma,n_{0},k_{0},\ldots,n_{t-1},k_{t-1},n_{t},k_{t}\right).
$$
In the right column this prior is shown in gray for comparison. - The density curves in the right column are narrower than the corresponding likelihood curves in the middle column. This increase in precision is what we gain from the informative prior in the left column.
- Except for row 0, each density curve in the left column is obtained by taking the density curve in the right column from the previous row (time step)—\(f\left(p_{t-1}\mid\cdots\right)\)—and making it a bit wider. (This necessarily lowers the peak of the curve, as the area under the curve must still be 1.) To understand this, recall that the left column is the inferred posterior for \(p_{t}\) given only the data up to the previous time step \(t-1\). Then all we know about \(p_{t}\) is whatever we know about \(p_{t-1}\), plus the fact that \(\mathrm{logit}\left(p_{t}\right)\) differs from \(\mathrm{logit}\left(p_{t-1}\right)\) by an amount that has a variance of \(\sigma^{2}\):
$$
\alpha_{t}\sim\mathrm{Normal}\left(\alpha_{t-1},\sigma\right)
$$
The density curve \(f(p_{t-1}\mid\cdots)\) is shown in gray in the left column for comparison.
Of course, in reality we don’t know \(\sigma\) and must infer it instead. Figure 5 repeats the analysis of Figure 4, except that each plot shows a joint probability distribution for \(\sigma\) and \(p_{t}\).
- The left column is \(f\left(p_{t},\sigma\mid n_{0},k_{0},\ldots,n_{t-1},k_{t-1}\right)\).
- The middle column is the likelihood \(\Pr\left(k_{t}\mid n_{t},p_{t}\right)\).
- The right column is \(f\left(p_{t},\sigma\mid n_{0},k_{0},\ldots,n_{t},k_{t}\right)\).
- \(t\) increases from \(0\) to \(4\) from top to bottom.
- The \(y\) axis is \(\sigma\), the \(x\) axis is \(p_{t}\), and brighter shading indicates a higher probability density.
- The range for \(\sigma\) is \(0\) to \(0.45\).
Note the following:
- The “probability clouds” in the right column lean to the right. This is because the data indicate that \(p_{t}\) is increasing with \(t\) (note that the center of the likelihood moves to the right as \(t\) increases), but a near-zero value for \(\sigma\) doesn’t allow for much change in \(p_{t}\).
- As \(t\) increases we get more evidence for a nonzero value of \(\sigma\), and the “probabily clouds” move up away from the \(x\) axis.

Figure 5
A Computational Example
To help readers understand this model and the Bayesian concepts I’ve written an R script, binom-llm-comp-examp.R, that computes various posterior densities and posterior probabilities up to time step 3, exactly as described earlier. The script is intended to be read as well as run; hence the emphasis is on clarity rather than speed. In particular, since some functions compute integrals over upwards of four variables using a generic integration procedure, for each point in a density plot, some of the computations can take several minutes. Do not be daunted by the length of the script; it is long because half of it is comments, and little effort has been made to factor out common code as I judged it better to be explicit than brief. The script is grouped into blocks of short functions that are all minor variations of the same pattern; once you’ve read the first few in a block, you can skim over the rest.
Here are the steps to use the script:
- Save
binom-llm-comp-examp.Rto some folder. - Start up R.
- Issue the command
source('folder/binom-llm-comp-examp.R'),
replacingfolderwith the path to the folder where you savedbinom-llm-comp-examp.R. - Issue the command
demo(). This runs a demo showing the various commands the script provides. - Experiment with these commands, using different data values or intervals.
The following list describes the available commands. \(\Delta_{1}\) is \(p_{1}-p_{0}\), \(\Delta_{2}\) is \(p_{2}-p_{0}\), and \(\Delta_{3}\) is \(p_{3}-p_{0}\). In general, any time a command takes parameters \(k\) and \(n\), these are the survey data: \(k\) is a vector containing the count of positive responses for each time step, and \(n\) is a vector containing the sample size for each time step. Note that \(k[1]\) contains \(k_{0}\) (the count for time step 0), \(k[2]\) contains \(k_{1}\), etc., and similarly for \(n\).
-
print.config()Prints the values of various control parameters, prior parameters, and data values that you can modify. -
plot.p0.posterior.density(k,n)Plots the posterior density \(f\left(p_{0}\mid k_{0},n_{0}\right)\). -
p0.posterior.probability(a,b,k,n)Computes the posterior probability \(\Pr\left(a\leq p_{0}\leq b\mid k_{0},n_{0}\right)\). -
plot.p1.posterior.density(k,n)Plots the posterior density \(f\left(p_{1}\mid k_{0},n_{0},k_{1},n_{1}\right)\). -
p1.posteror.probability(a,b,k,n)Computes the posterior probability
$$
\Pr\left(a\leq p_{1}\leq b\mid k_{0},n_{0},k_{1},n_{1}\right).
$$ -
plot.delta1.posterior.density(k,n)Plots the posterior density
\(f\left(\Delta_{1}\mid k_{0},n_{0},k_{1},n_{1}\right)\). -
delta1.posterior.probability(a,b,k,n)Computes the posterior
probability
$$
\Pr\left(a\leq\Delta_{1}\leq b\mid k_{0},n_{0},k_{1},n_{1}\right).
$$ -
plot.p2.posterior.density(k,n)Plots the posterior density \(f\left(p_{2}\mid k_{0},n_{0},k_{1},n_{1},k_{2},n_{2}\right)\). -
p2.posteror.probability(a,b,k,n)Computes the posterior probability
$$
\Pr\left(a\leq p_{2}\leq b\mid k_{0},n_{0},k_{1},n_{1},k_{2},n_{2}\right).
$$ -
plot.delta2.posterior.density(k,n)Plots the posterior density
\(f\left(\Delta_{2}\mid k_{0},n_{0},k_{1},n_{1},k_{2},n_{2}\right)\). -
delta2.posterior.probability(a,b,k,n)Computes the posterior probability
$$
\Pr\left(a\leq\Delta_{2}\leq b\mid k_{0},n_{0},k_{1},n_{1},k_{2},n_{2}\right).
$$ -
plot.p3.posterior.density(k,n)Plots the posterior density \(f\left(p_{3}\mid k_{0},n_{0},k_{1},n_{1},k_{2},n_{2},k_{3},n_{3}\right)\). -
p3.posteror.probability(a,b,k,n)Computes the posterior probability
$$
\Pr\left(a\leq p_{3}\leq b\mid k_{0},n_{0},k_{1},n_{1},k_{2},n_{2},k_{3},n_{3}\right).
$$ -
plot.delta3.posterior.density(k,n)Plots the posterior density
\(f\left(\Delta_{3}\mid k_{0},n_{0},k_{1},n_{1},k_{2},n_{2},k_{3},n_{3}\right)\). -
delta3.posterior.probability(a,b,k,n)Computes the posterior probability
$$
\Pr\left(a\leq\Delta_{3}\leq b\mid k_{0},n_{0},k_{1},n_{1},k_{2},n_{2},k_{3},n_{3}\right).
$$References
[mcmc]Brooks, S., A. Gelman, G. Jones, and X.-L. Meng (2011). Handbook of Markov Chain Monte Carlo.
[cox]Cox, R. T. (1946). “Probability, frequency and reasonable expectation,” American Journal of Physics 17, 1–13.
[time-series]Durbin, J. and S. J. Koopman (2012). Time Series Analysis by State Space Methods, second edition.
[jaynes]Jaynes, E. T. (2003). Probability Theory: The Logic of Science.
A Review of Integrals and Probability Densities
Here is a review of some concepts from probability theory and calculus that are especially important in Bayesian statistics.
One-dimensional integrals and probability densities
An integral can be thought of as a sum over a grid of values, multiplied by the spacing of the grid. This is useful in combination with the notion of a probability density function when you want to compute the probability that a random variable lies in some interval.
If \(f(x)\) is a probability density function for some variable \(X\), and \(a<b\), then the probability that \(a<X<b\) is the integral
\(\displaystyle \Pr\left(a<X<b\right)=\int_{a}^{b}f(x)\,\mathrm{d}x; \)
this may be thought of as a short-hand notation for
\(\displaystyle \sum_{i=1}^{N}f\left(x_{i}\right)\,\mathrm{d}x \)
for some very large number \(N\), where
\(\displaystyle \begin{eqnarray*} x_{i} & = & a+\left(i-\frac{1}{2}\right)\mathrm{d}x\\ \mathrm{d}x & = & \frac{b-a}{N}. \end{eqnarray*}\)
If we chop the interval from \(a\) to \(b\) into \(N\) equal-sized subintervals, then \(x_{i}\) is the midpoint of the \(i\)-th subinterval, and \(\mathrm{d}x\) is the width of each of these subintervals. The values \(x_{1},\ldots,x_{N}\) form a grid of values, and \(\mathrm{d}x\) is the spacing of the grid. If the grid spacing is so fine that \(f(x)\) is nearly constant over each of these subintervals, then the probability that \(X\) lies in subinterval \(i\) is closely approximated as \(f\left(x_{i}\right)\mathrm{d}x\). We get \(\Pr\left(a<X<b\right)\) by adding up the probabilities for each of the subintervals. Figure 1 illustrates this process with \(a=0\) and \(b=1\) for a variable with a normal distribution with mean 0 and variance 1.

Figure 1
The exact probability \(\Pr\left(0<X<1\right)\) is the integral \(\int_{0}^{1}\phi(x)\,\mathrm{d}x\), which is the area under the normal density curve between \(x=0\) and \(x=1\). (\(\phi(x)\) is the probability density for the normal distribution at \(x\).) The figure illustrates an approximate computation of the integral using \(N=5\). The subintervals have width \(\mathrm{d}x=0.2\) and their midpoints are \(x_{1}=0.1\), \(x_{2}=0.3\), \(x_{3}=0.5\), \(x_{4}=0.7\), and \(x_{5}=0.9\). The five rectangles each have width \(\mathrm{d}x\), and their heights are \(\phi\left(x_{1}\right)\), \(\phi\left(x_{2}\right)\), \(\phi\left(x_{3}\right)\), \(\phi\left(x_{4}\right)\), and \(\phi\left(x_{5}\right)\). The sum \(\phi\left(x_{1}\right)\mathrm{d}x+\cdots+\phi\left(x_{5}\right)\mathrm{d}x\) is the total area of the five rectangles combined; this sum is an approximation of \(\int_{0}^{1}\phi(x)\,\mathrm{d}x\). As \(N\) gets larger the rectangles get thinner, and the approximation becomes closer to the true area under the curve.
Please note that the process just described defines what the integral means, but in practice more efficient algorithms are used for the actual computation.
The probability that \(X>a\) is
\(\displaystyle \Pr\left(a<X<\infty\right)=\int_{a}^{\infty}f(x)\,\mathrm{d}x; \)
you can think of this integral as being \(\int_{a}^{b}f(x)\,\mathrm{d}x\) for some very large value \(b\), chosen to be so large that the probability density \(f(x)\) is vanishingly small whenever \(x\geq b\).
Multi-dimensional integrals and probability densities
We can also have joint probability distributions for two variables \(X_{1}\) and \(X_{2}\) with a corresponding joint probability density function \(f\left(x_{1},x_{2}\right)\). If \(a_{1}<b_{1}\) and \(a_{2}<b_{2}\), then the probability that \(a_{1}<X_{1}<b_{1}\) and \(a_{2}<X_{2}<b_{2}\) is the nested integral
\(\displaystyle \Pr\left(a_{1}<X_{1}<b_{1},a_{2}<X_{2}<b_{2}\right)=\int_{a_{1}}^{b_{1}}\int_{a_{2}}^{b_{2}}f\left(x_{1},x_{2}\right)\,\mathrm{d}x_{2}\,\mathrm{d}x_{1}; \)
analogously to the one-dimensional case, this two-dimensional integral may be thought of as the following procedure:
- Choose very large numbers \(N_{1}\) and \(N_{2}\).
- Chop the interval from \(a_{1}\) to \(b_{1}\) into \(N_{1}\) equal subintervals, and chop the interval from \(a_{2}\) to \(b_{2}\) into \(N_{2}\) equal subintervals, so that the rectangular region defined by \(a_{1}\leq x_{1}\leq b_{1}\) and \(a_{2}\leq x_{2}\leq b_{2}\) is divided into \(N_{1}N_{2}\) very small boxes.
- Let \(\left(x_{1i},x_{2j}\right)\) be the midpoint of the box at the intersection of the \(i\)-th row and \(j\)-th column. These midpoints form a two-dimensional grid.
- Let \(\mathrm{d}x_{1}=\left(b_{1}-a_{1}\right)/N_{1}\) and \(\mathrm{d}x_{2}=\left(b_{2}-a_{2}\right)/N_{2}\); note that \(\mathrm{d}x_{1}\) is the width and \(\mathrm{d}x_{2}\) is the height of each of the very small boxes.
- Sum up the values \(f\left(x_{1i},x_{2j}\right)\,\mathrm{d}x_{1}\,\mathrm{d}x_{2}\) for all \(i\) and \(j\), \(1\leq i\leq N_{1}\) and \(1\leq j\leq N_{2}\).
Figure 2 shows an example of a joint probability density for \(X_{1}\) and \(X_{2}\), displayed using shades of gray, with lighter colors indicating a greater probability density. The joint distribution shown is a multivariate normal centered at \(X_{1}=2\) and \(X_{2}=1\), with covariance matrix
\(\displaystyle \Sigma=\begin{pmatrix}1.0 & 0.3\\ 0.3 & 0.5 \end{pmatrix}. \)
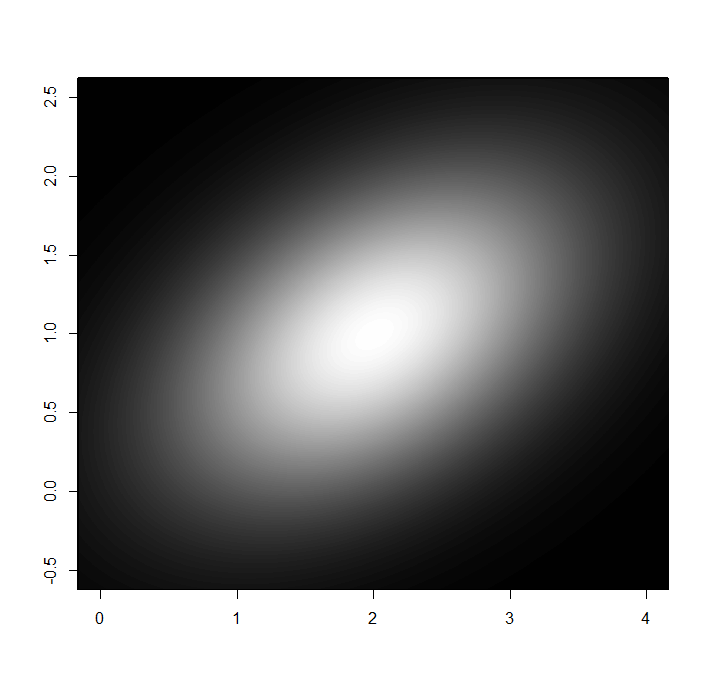
Figure 2
Figure 3 illustrates the process of computing \(\Pr\left(2<X_{1}<4,\,1<X_{2}<2\right)\) when \(X_{1}\) and \(X_{2}\) have the above joint density, using \(N_{1}=8\) and \(N_{2}=5\).
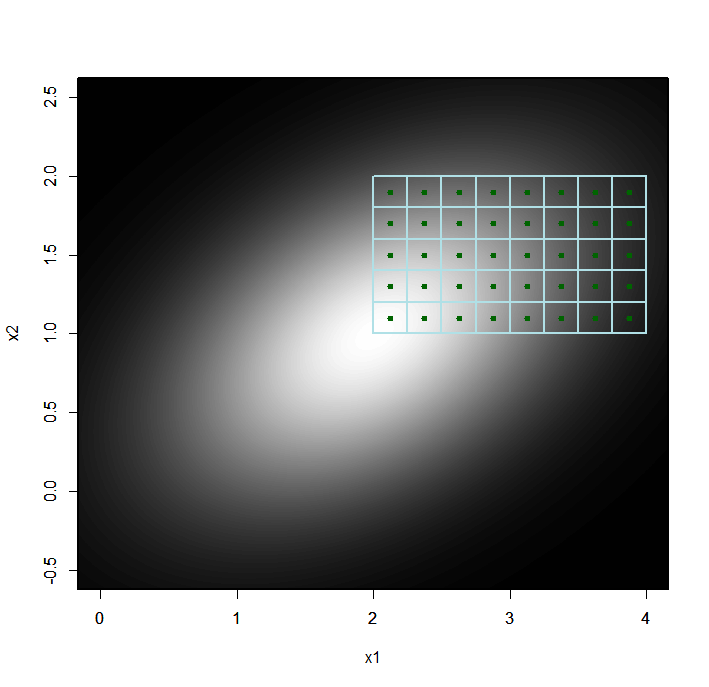
Figure 3
We can, of course, generalize this to joint distributions over three, four, or more variables \(X_{1},\ldots,X_{n}\), with a corresponding joint probability density function \(f\left(x_{1},\ldots,x_{n}\right)\). If \(a_{1}<b_{1}\) and … and \(a_{n}<b_{n}\), then the probability that \(a_{1}<X_{1}<b_{1}\) and … and \(a_{n}<X_{n}<b_{n}\) is the nested integral
\(\displaystyle \Pr\left(a_{1}<X_{1}<b_{1},\ldots,a_{n}<X_{n}<b_{n}\right)=\int_{a_{1}}^{b_{1}}\cdots\int_{a_{n}}^{b_{n}}f\left(x_{1},\ldots,x_{n}\right)\,\mathrm{d}x_{n}\,\cdots\,\mathrm{d}x_{1} \)
and we can think of this as choosing very large numbers \(N_{1},\ldots,N_{n}\) and forming an \(n\)-dimensional grid with \(N_{1}\times\cdots\times N_{n}\) cells, evaluating \(f\left(x_{1},\ldots,x_{n}\right)\) at the midpoint of each of these cells, and so on.
Conditional probability densities
Suppose that we have variables \(X_{1}\) and \(X_{2}\) with a joint distribution that has density function \(f\left(x_{1},x_{2}\right)\), describing our prior information about \(X_{1}\) and \(X_{2}\). We then find out the value of \(X_{1}\), perhaps via some sort of a measurement. Our updated information about \(X_{2}\) is summarized in the conditional distribution for \(X_{2}\), given that \(X_{1}=x_{1}\); the density function for this conditional distribution is
\(\displaystyle f\left(x_{2}\mid x_{1}\right)=\frac{f\left(x_{1},x_{2}\right)}{\int_{-\infty}^{\infty}f\left(x_{1},x_{2}\right)\,\mathrm{d}x_{1}}. \)
For example, if \(X_{1}\) and \(X_{2}\) have the joint distribution described in Figure 3, then Figure 4 shows the conditional density function for \(X_{2}\) given \(X_{1}=1\), and Figure 5 shows the conditional density function for \(X_{2}\) given \(X_{1}=3\). You can see from the density plot that \(X_{1}\) and \(X_{2}\) are positively correlated, and this explains why the density curve for \(X_{2}\) given \(X_{1}=3\) is shifted to the right relative to the density curve for \(X_{2}\) given \(X_{1}=1\).

Figure 4

Figure 5
In general, if we have joint probability distribution for \(n\) variables \(X_{1},\ldots,X_{n}\), with a joint probability density function \(f\left(x_{1},\ldots,x_{n}\right)\), and we find out the values of, say, \(X_{m+1},\ldots,X_{n}\), then we write
\(\displaystyle f\left(x_{1},\ldots,x_{m}\mid x_{m+1},\ldots,x_{n}\right) \)
for the conditional density function for \(X_{1},\ldots,X_{m}\), given that \(X_{m+1}=x_{m+1},\ldots,X_{n}=x_{n}\), and its formula is
\(\displaystyle f\left(x_{1},\ldots,x_{m}\mid x_{m+1},\ldots,x_{n}\right)=\frac{f\left(x_{1},\ldots,x_{n}\right)}{\int_{-\infty}^{\infty}\cdots\int_{-\infty}^{\infty}f\left(x_{1},\ldots,x_{n}\right)\,\mathrm{d}x_{m+1}\,\cdots\,\mathrm{d}x_{n}}. \)
One way of understanding this formula is to realize that if you integrate the conditional density over all possible values of \(X_{1},\ldots,X_{n}\), the result must be 1 (one of those possible values must be the actual value), and this is what the denominator in the above formula guarantees.
Change of variables
Suppose that we have two variables \(x\) and \(y\) that have a known deterministic relation that allows us to always obtain the value of \(y\) from the value of \(x\), and likewise obtain the value of \(x\) from the value of \(y\). Some examples are
- \(y=2x\) and \(x=\frac{1}{2}y\),
- \(y=e^{x}\) and \(x=\ln(y)\), or
- \(y=x^{3}\) and \(x=y^{1/3}\),
but not \(y=x^{2}\) when \(x\) may be positive or negative: if we are given \(y\) then \(x\) could be either \(+\sqrt{y}\) or \(-\sqrt{y}\).
If we have a probability density \(f_{\mathrm{y}}\) for \(y\) then we can turn it into a probability density \(f_{\mathrm{x}}\) for \(x\) using the change of variables formula:
\(\displaystyle f_{\mathrm{x}}(x)=f_{\mathrm{y}}(y)\left|\frac{\mathrm{d}y}{\mathrm{d}x}\right|. \)
In the above formula, \(\mathrm{d}y/\mathrm{d}x\) stands for the derivative of \(y\) with respect to \(x\); this measures how much \(y\) changes relative to a change in \(x\), and in general it depends on \(x\). Loosely speaking, imagine changing \(x\) by a vanishingly small amount \(\mathrm{d}x\), and let \(\mathrm{d}y\) be the corresponding (vanishingly small) change in \(y\); then the derivative of \(y\) with respect to \(x\) is the ratio \(\mathrm{d}y/\mathrm{d}x\).
Here are some common changes of variable:
- \(y=a\,x\) where \(a\) is some nonzero constant. Then
\(\displaystyle \begin{eqnarray*} \frac{\mathrm{d}y}{\mathrm{d}x} & = & a\\ f_{\mathrm{x}}(x) & = & a\,f_{\mathrm{y}}(y)\\ & = & a\,f_{\mathrm{y}}(ax). \end{eqnarray*}\)
- \(y=e^{x}\). Then
\(\displaystyle \begin{eqnarray*} \frac{\mathrm{d}y}{\mathrm{d}x} & = & y\\ f_{\mathrm{x}}(x) & = & y\,f_{\mathrm{y}}(y)\\ & = & e^{x}\,f_{\mathrm{y}}\left(e^{x}\right) \end{eqnarray*}\)
- \(y=\mathrm{logit}(x)=\ln(x/(1-x))\), where \(0<x<1\). Then
\(\displaystyle \begin{eqnarray*} \frac{\mathrm{d}y}{\mathrm{d}x} & = & \frac{1}{x\,(1-x)}\\ f_{\mathrm{x}}(x) & = & \frac{f_{\mathrm{y}}(y)}{x\,(1-x)}\\ & = & \frac{f_{\mathrm{y}}\left(\mathrm{logit}(x)\right)}{x\,(1-x)}. \end{eqnarray*}\)
Bayesian Sample Size Determination, Part 2
(Part 1 is here.)
In part 1 I discussed choosing a sample size for the problem of inferring a proportion. Now, instead of a parameter estimation problem, let’s consider a hypothesis test.
This time we have two proportions \(\theta_0\) and \(\theta_1\), and two hypotheses that we want to compare: \(H_=\) is the hypothesis that \(\theta_0 = \theta_1\), and \(H_{\ne}\) is the hypothesis that \(\theta_0 \ne \theta_1\). For example, we might be comparing the effects of a certain medical treatment and a placebo, with \(\theta_0\) being the proportion of patients who would recover if given the placebo, and \(\theta_1\) being the proportion of patients who would recover if given the medical treatment.
To fully specify the two hypotheses we must define their priors for \(\theta_0\) and \(\theta_1\). For appropriate values \(\alpha > 0\) and \(\beta > 0\) let us define
- \(H_=\): \(\theta_0 \sim \mathrm{beta}(\alpha,\beta)\) and \(\theta_1 = \theta_0\).
- \(H_{\ne}\): \(\theta_0 \sim \mathrm{beta}(\alpha, \beta)\) and \(\theta_1 \sim \mathrm{beta}(\alpha, \beta)\) independently.
(\(\mathrm{beta}(\alpha,\beta)\) is a beta distribution over the interval \((0,1)\).) Our data are
- \(n_0\) and \(k_0\): the number of trials in population 0 and the number of positive outcomes among these trials.
- \(n_1\) and \(k_1\): the number of trials in population 1 and the number of positive outcomes among these trials.
We also define \(n = n_0 + n_1\) and \(k = k_0 + k_1\).
To get the likelihood of the data conditional only on the hypothesis \(H_=\) or \(H_{\ne}\) itself, without specifying a particular value for the parameters \(\theta_0\) or \(\theta_1\), we must “sum” (or rather, integrate) over all possible values of the parameters. This is called the marginal likelihood. In particular, the marginal likelihood of \(H_=\) is
\( \displaystyle \begin{aligned} & \Pr(k_0, k_1 \mid n_0, n_1, H_=) \\ = & \int_0^1 \mathrm{beta}(\theta \mid \alpha, \beta)\, \Pr\left(k_0 \mid n_0, \theta\right) \, \Pr\left(k_1 \mid n_0,\theta\right) \,\mathrm{d}\theta \\ = & c_0 c_1 \frac{\mathrm{B}(\alpha + k, \beta + n – k)}{\mathrm{B}(\alpha, \beta)} \end{aligned} \)
where \(\mathrm{B}\) is the beta function (not the beta distribution) and
\(\displaystyle \begin{aligned}c_0 & = \binom{n_0}{k_0} \\ c_1 & = \binom{n_1}{k_1} \\ \Pr\left(k_i\mid n_i,\theta\right) & = c_i \theta^{k_i} (1-\theta)^{n_i-k_i}. \end{aligned} \)
The marginal likelihood of \(H_{\ne}\) is
\( \displaystyle \begin{aligned} & \Pr\left(k_0, k_1 \mid n_0, n_1, H_{\ne}\right) \\ = & \int_0^1\mathrm{beta}\left(\theta_0 \mid \alpha, \beta \right)\, \Pr\left(k_0 \mid n_0, \theta_0 \right) \,\mathrm{d}\theta_0\cdot \\ & \int_0^1 \mathrm{beta}\left(\theta_1 \mid \alpha, \beta \right) \, \Pr\left(k_1 \mid n_1, \theta_1 \right)\,\mathrm{d}\theta_1 \\ = & c_0 \frac{\mathrm{B}\left(\alpha + k_0, \beta + n_0 – k_0\right)}{\mathrm{B}(\alpha, \beta)} \cdot c_1 \frac{\mathrm{B}\left(\alpha + k_1, \beta + n_1 – k_1\right)}{\mathrm{B}(\alpha, \beta)}. \end{aligned} \)
Writing \(\Pr\left(H_=\right)\) and \(\Pr\left(H_{\ne}\right)\) for the prior probabilities we assign to \(H_=\) and \(H_{\ne}\) respectively, Bayes’ rule tells us that the posterior odds for \(H_=\) versus \(H_{\ne}\) is
\(\displaystyle \begin{aligned}\frac{\Pr\left(H_= \mid n_0, k_0, n_1, k_1\right)}{ \Pr\left(H_{\ne} \mid n_0, k_0, n_1, k_1\right)} & = \frac{\Pr\left(H_=\right)}{\Pr\left(H_{\ne}\right)} \cdot \frac{\mathrm{B}(\alpha, \beta) \mathrm{B}(\alpha + k, \beta + n – k)}{ \mathrm{B}\left(\alpha + k_0, \beta + n_0 – k_0\right) \mathrm{B}\left(\alpha + k_1, \beta + n_1 – k_1\right)}. \end{aligned} \)
Defining \(\mathrm{prior.odds} = \Pr\left(H_{=}\right) / \Pr\left(H_{\ne}\right)\), the following R code computes the posterior odds:
post.odds <- function(prior.odds, α, β, n0, k0, n1, k1) {
n <- n0 + n1
k <- k0 + k1
exp(
log(prior.odds) +
lbeta(α, β) + lbeta(α + k, β + n - k) -
lbeta(α + k0, β + n0 - k0) - lbeta(α + k1, β + n1 - k1))
}
We want the posterior odds to be either very high or very low, corresponding to high confidence that \(H_=\) is true or high confidence that \(H_{\ne}\) is true, so let’s choose as our quality criterion the expected value of the smaller of the posterior odds and its inverse:
$$ E\left[\min\left(\mathrm{post.odds}\left(k_0,k_1\right), 1/\mathrm{post.odds}\left(k_0,k_1\right)\right) \mid n_0, n_1, \alpha, \beta \right] $$
where, for brevity, we have omitted the fixed arguments to \(\mathrm{post.odds}\). As before, this expectation is over the prior predictive distribution for \(k_0\) and \(k_1\).
In this case the prior predictive distribution does not have a simple closed form, and so we use a Monte Carlo procedure to approximate the expectation:
- For \(i\) ranging from \(1\) to \(N\),
- Draw \(h=0\) with probability \(\Pr\left(H_=\right)\) or \(h=1\) with probability \(\Pr\left(H_{\ne}\right)\).
- Draw \(\theta_0\) from the \(\mathrm{beta}(\alpha, \beta)\) distribution.
- If \(h=0\) then set \(\theta_1 = \theta_0\); otherwise draw \(\theta_1\) from the \(\mathrm{beta}(\alpha, \beta)\) distribution.
- Draw \(k_0\) from \(\mathrm{binomial}\left(n_0, \theta_0\right)\) and draw \(k_1\) from \(\mathrm{binomial}\left(n_1, \theta_1\right)\).
- Define \(z = \mathrm{post.odds}\left(k_0, k_1\right)\).
- Assign \(x_i = \min(z, 1/z)\).
- Return the average of the \(x_i\) values.
The following R code carries out this computation:
loss <- function(prior.odds, α, β, n0, k0, n1, k1) {
z <- post.odds(prior.odds, α, β, n0, k0, n1, k1);
pmin(z, 1/z)
}
expected.loss <- function(prior.odds, α, β, n0, n1) {
# prior.odds = P.eq / P.ne = (1 - P.ne) / P.ne = 1/P.ne - 1
# P.ne = 1 / (prior.odds + 1)
N <- 1000000
h <- rbinom(N, 1, 1 / (prior.odds + 1))
θ0 <- rbeta(N, α, β)
θ1 <- rbeta(N, α, β)
θ1[h == 0] <- θ0[h == 0]
k0 <- rbinom(N, n0, θ0)
k1 <- rbinom(N, n1, θ1)
x <- loss(prior.odds, α, β, n1, k1, n0, k0)
# Return the Monte Carlo estimate +/- error estimate
list(estimate=mean(x), delta=sd(x)*1.96/sqrt(N))
}
Suppose that \(H_=\) and \(H_{\ne}\) have equal prior probabilities, and \(\alpha=\beta=1\), that is, we have a uniform prior over \(\theta_0\) (and \(\theta_1\), if applicable). The following table shows the expected loss—the expected value of the minimum of the posterior odds against \(H_{\ne}\) and the posterior odds against \(H_=\)—as \(n_0 = n_1\) ranges from 200 to 1600:
| \(n_0\) | \(n_1\) | Expected loss |
|---|---|---|
| 200 | 200 | 0.130 |
| 400 | 400 | 0.095 |
| 600 | 600 | 0.078 |
| 800 | 800 | 0.069 |
| 1000 | 1000 | 0.062 |
| 1200 | 1200 | 0.057 |
| 1400 | 1400 | 0.053 |
| 1600 | 1600 | 0.050 |
We find that it takes 1600 trials from each population to achieve an expected posterior odds in favor of the (posterior) most probable results of 20 to 1.
Bayesian Sample Size Determination, Part 1
I recently encountered a claim that Bayesian methods could provide no guide to the task of estimating what sample size an experiment needs in order to reach a desired level of confidence. The claim was as follows:
- Bayesian theory would have you run your experiment indefinitely, constantly updating your beliefs.
- Pragmatically, you have resource limits so you must determine how best to use those limited resources.
- Your only option is to use frequentist methods to determine how large of a sample you’ll need, and then to use frequentist methods to analyze your data.
(2) above is correct, but (1) and (3) are false. Bayesian theory allows you to run your experiment indefinitely, but in no way requires this. And Bayesian methods not only allow you to determine a required sample size, they are also far more flexible than frequentist methods in this regard.
For concreteness, let’s consider the problem of estimating a proportion:
- We have a parameter \(\theta\), \(0 \leq \theta \leq 1\), which is the proportion to estimate.
- We run an experiment \(n\) times, and \(x_i\), \(1 \leq i \leq n\) is the outcome of experiment \(i\). This outcome may be 0 or 1.
- Our statistical model is \(x_i \sim \mathrm{Bernoulli}(\theta) \) for all \(1 \leq i \leq n\), that is,
- \(x_i = 1\) with probability \(\theta\),
- \(x_i = 0\) with probability \(1-\theta\), and
- \(x_i\) and \(x_j\) are independent for \(i \ne j\).
- We are interested in the width \(w\) of the 95% posterior credible interval for \(\theta\).
For example, we could be running an opinion poll in a large population, with \(x_i\) indicating an answer of yes=1 or no=0 to a survey question. Each “experiment” is an instance of getting an answer from a random survey respondent, \(n\) is the number of people surveyed, and \(k\) is the number of “yes” answers.
We’ll use a \(\mathrm{beta}(\alpha,\beta)\) prior \((\alpha,\beta>0)\) to describe our prior information about \(\theta\). This is a distribution over the interval \([0,1]\) with mean \(\alpha/\beta\) and a shape determined by \(\alpha\); higher values of \(\alpha\) correspond to more sharply concentrated distributions.
If \(\alpha=\beta=1\) then we have a uniform distribution over \([0,1]\). If \(\alpha=\beta=10\) then \(\mathrm{beta}(\alpha,\beta)\) is the following distribution with mean 0.5:
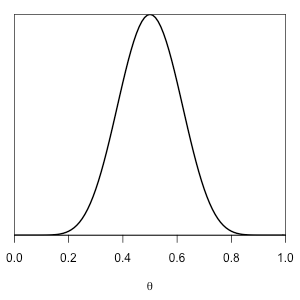
Such a prior might be appropriate, for example, for an opinion poll on a topic for which you expect to see considerable disagreement.
If \(\alpha=1,\beta=4\) then \(\mathrm{beta}(\alpha,\beta)\) is the following distribution with mean 0.2:
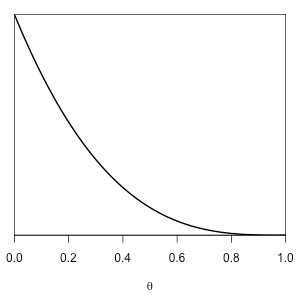
If we have \(k\) positive outcomes out of \(n\) trials, then our posterior distribution for \(\theta\) is \(\mathrm{beta}(\alpha+k,\beta+n-k)\), and the 95% equal-tailed posterior credible interval is the difference between the 0.975 and 0.025 quantiles of this distribution; we compute this in R as
w <- qbeta(.975, α + k, β + n - k) - qbeta(.025, α + k, β + n - k)
If you prefer to think in terms of \(\hat{\theta}\pm\Delta\), a point estimate \(\hat{\theta}\) plus or minus an error width \(\Delta\), then choosing \(\hat{\theta}\) to be the midpoint of the 95% credible interval gives \(\Delta=w/2\).
Note that \(w\) depends on both \(n\), the number of trials, and \(k\), the number of positive outcomes we observe; hence we write \(w = w(n,k)\). Although we may choose \(n\) in advance, we do not know what \(k\) will be. However, combining the prior for \(\theta\) with the distribution for \(k\) conditional on \(n\) and \(\theta\) gives us a prior predictive distribution for \(k\):
$$ \Pr(k \mid n) = \int_0^1\Pr(k \mid n,\theta) \mathrm{beta}(\theta \mid \alpha, \beta)\,\mathrm{d}\theta. $$
\(\Pr(k \mid n, \theta)\) is a binomial distribution, and the prior predictive distribution \(\Pr(k \mid n)\) is a weighted average of the binomial distributions for \(k\) you get for different values of \(\theta\), with the prior density serving as the weighting. This weighted average of binomial distributions is known as the beta-binomial distribution \(\mathrm{betabinom}(n,\alpha,\beta)\).
So we use as our quality criterion \(E[w(n,k) \mid n, \alpha, \beta]\), the expected value of the posterior credible interval width \(w\), using the prior predictive distribution \(\mathrm{betabinom}(n,\alpha,\beta)\) for \(k\). The file edcode1.R contains R code to compute this expected posterior width for arbitrary choices of \(n\), \(\alpha\), and \(\beta\).
Here is a table of our quality criterior computed for various values of \(n\), \(\alpha\), and \(\beta\):
| \(n\) | \(\alpha\) | \(\beta\) | \(E[w(n,k)\mid n,\alpha,\beta]\) | \(E[\Delta(n,k)\mid n,\alpha,\beta]\) |
|---|---|---|---|---|
| 100 | 1 | 1 | 0.152 | 0.076 |
| 200 | 1 | 1 | 0.108 | 0.054 |
| 300 | 1 | 1 | 0.089 | 0.044 |
| 100 | 10 | 10 | 0.174 | 0.087 |
| 200 | 10 | 10 | 0.129 | 0.064 |
| 300 | 10 | 10 | 0.107 | 0.053 |
| 100 | 1 | 4 | 0.131 | 0.066 |
| 200 | 1 | 4 | 0.094 | 0.047 |
| 300 | 1 | 4 | 0.077 | 0.039 |
We could then create a table such as this and choose a value for \(n\) that gave an acceptable expected posterior width. But we can do so much more…
This problem is a decision problem, and hence the methods of decision analysis are applicable here. The Von Neumann – Morgenstern utility theorem tells us that any rational agent make its choices as if it were maximizing an expected utility function or, equivalently, minimizing an expected loss function. For this problem, we can assume that
- The cost of the overall experiment increases as \( n \) increases; thus our loss function increases with \( n \).
- We prefer knowing \( \theta \) with more certainty over knowing it with less certainty; thus our loss function increases with \( w \), where \( w \) is the width of the 95% credible interval for \( \theta \).
This suggests a loss function of the form
$$ L(n, w) = f(n) + g(w) $$
where \(f\) and \(g\) are strictly increasing functions. If we must choose \(n\) in advance, then we should choose it so as to minimize the expected loss
$$ E[L(n,w)] = f(n) + E[g(w)]. $$
which we can compute via a slight modification to the code in edcode1.R:
expected.loss <- function(α, β, n) {
f(n) + sum(dbetabinom.ab(0:n, n, α, β) * g(posterior.width(α, β, n, 0:n)))
}
For example, suppose that this is a survey. If each response costs us $2, then \(f(n)=2n\). Suppose that \(g(w)=10^5w^2\), i.e., we would be willing to pay \(10^5(0.10)^2 – 10^5(0.05)^2\) or $750 to decrease the posterior width from 0.10 to 0.05. If a \(\mathrm{beta}(10,10)\) distribution describes our prior information, then the following plot shows the expected loss for \(n\) ranging from 1 to 1000,
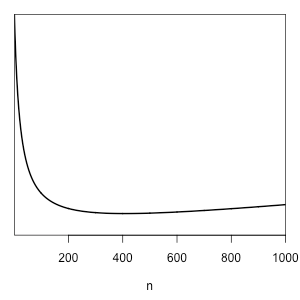 and \(n=407\) is the optimal choice.
and \(n=407\) is the optimal choice.
Noah and the Flood
This is a topic I just have to comment on, given the recent movie Noah and some comments I have heard from family members. I find it astounding that an educated, intelligent person, especially one with a degree in engineering or a hard science, could believe that the story of Noah and the Flood in Genesis is a literal, historical account. The only evidence in favor of it is an ancient legend recounted in the Bible and the story of Gilgamesh. Everything else argues against it. This is not a question of just one or two anomalies; the story falls to pieces pretty much however you approach it.
Others have already gone over this ground in detail, so I’ll just link to one of these articles—The Impossible Voyage of Noah’s Ark—and mention a few obvious problems that occur to me.
First, let’s talk prior plausibility.
How plausible is it that a construction crew of at most 8 people could build a wooden vessel much larger than any ever constructed in the 4500 years since, using pre-industrial, Bronze Age technology?
Assuming an 18-inch cubit, the Bible claims that the ark measured 450 feet long, 75 feet wide, and 45 feet high, that it was made out of “gopher wood,” and that it was sealed with pitch, presumably to keep it water tight. The ark as described in the Bible is essentially a barge, so I did a quick web search on the largest wooden ships ever built, and the closest thing I could find to the claimed size of Noah’s ark was the Pretoria, a huge barge built in 1900.
At the time of its construction, the Pretoria was the largest wooden ship that had ever been built, and is nearly the largest wooden ship of any kind ever built. Nevertheless, the Pretoria measured considerably smaller than the claimed dimensions of Noah’s ark: 338 feet long, 44 feet wide wide, and 23 feet in depth, or just under 1/4 the claimed total volume for Noah’s ark. Like other such large wooden ships, the Pretoria’s frame and hull required strengthening with steel plates and bands, along with a steam engine to pump out the water that leaked in. According to the 1918 book How Wooden Ships Are Built (by Harvey Cole Estep), “If current practice is any guide, it may safely be stated that steel reinforcement is necessary for hulls over 275 feet in length and exceeding, say, 3500 tons dead weight.”
Then there’s the question of where all that water came from, and where it went. A simple calculation shows that it would require about an additional 4.5 billion cubic kilometers of water to cover the whole Earth up to the top of Mount Everest, or nearly 3-1/2 times the current total volume of the world’s oceans. If you want to hypothesize that somehow such high mountains didn’t exist prior to the Flood, and were raised up afterwards, then you have several severe problems:
- Every time you add a new ad hoc addendum to your hypothesis to patch up a hole in the story, this as a logical necessity lowers the prior probability of the overall scenario.
- The best geological evidence says that the Himalayas are about 50 million years old. They were definitely around at the time of the presumed Flood.
- If you want to argue, against the geologic evidence, that somehow the Himalayas weren’t raised up until after 2500 B.C., consider the energies involved! If you want to raise up the Himalayas in at most a few hundred years, instead over 50 million years, you are talking continual, massive earthquakes for that entire period, and I’m guessing that the heat produced would melt a substantial portion of the Earth’s crust.
Second, let’s consider expected consequences.
An obvious one is that archaeologists and paleontologists should be finding a very large number of scattered human and other animal skeletons all dating to the same time period of about 2500 B.C. Needless to say, they have found nothing like this.
There should be obvious signs in the geologic record of such a massive cataclysm, evidence that can be dated to about 4500 years ago. No such evidence exists.
The Bronze Age spans the years from 3300 B.C. to 1200 B.C. in the near East. See, for example, the Bronze Age article in the Ancient HIstory Encyclopedia. Do archaeologists find the civilizations of that era suddenly disappearing around 2500 B.C.? No, they do not.
Some fish live only in salt water, others only in fresh water. The flood described in the Bible would have either killed all of the salt-water fish (if the flood waters were fresh) or killed all of the fresh-water fish (if the flood waters were salty) or both (if the flood waters were of intermediate salinity).
What happens when you reduce an entire species down to a very small breeding population? Usually, it dies out—see the notion of a minimum viable population. But if the species avoids that fate, you get something like the cheetahs: an entire species whose members are all virtually identical genetic copies of each other. A world in which the Biblical Flood had really occurred would look very different from ours. Every animal species would consist entirely of near-identical duplicates. There would be no racial strife among humans, because we would all look nearly as alike as identical twins.
I’ve just scratched the surface here, without hardly trying. Anyone who actually sits down and thinks about it, and does a bit of honest research will have no trouble finding many more problems with the whole Flood story.
Absence of Expected Evidence is Evidence of Absence
It is often claimed, with a triumphant air of finality, that “you can’t prove a negative.” Along similar lines it is often said, as if it were an unquestionable truth acknowledged by all, that “absence of evidence is not evidence of absence.”
Both of these supposed rules are epistemic nonsense.
You can prove that something doesn’t exist, and absence of some kinds of evidence is in fact evidence of absence. These are straightforward consequences of elementary probability theory.
Let’s first dispense with some obvious straw men. One might say, “Of course you can prove a negative; for example, it’s easy to prove that there does not exist any real number whose square is negative.” But that is a proof about the world of mathematical abstractions; when people say that you can’t prove a negative, they have in minding proving nonexistence of some entity or phenomenon in the physical world. This is the more interesting case that I am addressing here.
The second straw man goes in the other direction: it is true, in a vacuous and utterly uninteresting sense, that you can’t prove nonexistence of a hypothesized phenomenon or entity with 100% certainty… but this is only true in the same sense that you can’t prove any claim about the physical world with 100% certainty. For example, I could claim that you are not actually reading these words, but are instead experiencing an elaborate hallucination as you drool in your padded cell in a mental institution. You cannot prove, with absolute certainty, that this is not the case. Absolute proof is reserved to the realm of mathematics only. In assessing claims about the physical world we are always working with imperfect information, and so the relevant question is not, can you prove that X is true, but rather, how probable is it that X is true?
So let’s agree that “prove,” in the context of assertions about the physical world, in practice means “demonstrate that a high degree of confidence is warranted.”
So how can you prove a negative, and how can you use absence of evidence as evidence of absence? The key lies in considering the probable consequences of a hypothesis. Consider the hypothesis, “There is a cat living in my apartment.” If this hypothesis is true, then I would expect to observe the following:
- Urine stains somewhere in the apartment; the cat has to pee sometime.
- Feces of a certain size appearing from time to time; the cat is going to have bowel movements.
- Food going missing; the cat has to eat sometime. Or, if the cat doesn’t eat, it’s going to die, and I expect the bad smell of a decomposing body to eventually become evident.
- Scratched up furniture or other items; it’s an established behavioral pattern of cats that they scratch things.
- Unexplained sounds of movement. It’s unlikely that the cat can be so thoroughly stealthy that, aside from never seeing it, I never even hear it.
- Loose animal hairs on the carpet or in other areas around the apartment.
- Sneezing, itching, and a runny nose even when I’m not suffering a cold and it’s not allergy season. (I’m allergic to cat dander.)
If I observe none of these expected consequences of a cat living in my apartment, I can be very confident that there is, in fact, no cat living in my apartment. I have proven a negative through a lack of evidence.
Notice the form of this logical rule: absence of expected evidence is evidence of absence. If I did not expect to have this evidence—say, because I haven’t even entered the apartment for the last three months—then its absence would be meaningless.
For an entertaining fictional illustration of this idea, let’s look at the Sherlock Holmes story, “Silver Blaze.” A race horse has been stolen and its trainer killed. Suspicion is laid upon a man named Fitzroy Simpson. Holmes argues that Simpson could have been present in the stables that night:
Gregory (Scotland Yard detective): “Is there any other point to which you would wish to draw my attention?”
Holmes: “To the curious incident of the dog in the night-time.”
Gregory: “The dog did nothing in the night-time.”
Holmes: “That was the curious incident.”
As Holmes later explained,
…a dog was kept in the stables, and yet, though some one had been in and fetched out a horse, he had not barked enough to arouse the two lads in the loft. Obviously the midnight visitor was some one whom the dog knew well.
(You can stop here if the above intuitive explanation satisfies you.) Here’s the math, for those who are interested:
$$ \frac{\Pr(A \mid \neg D, X)}{\Pr(\neg A \mid \neg D,X)} = \frac{\Pr(A \mid X)}{\Pr(\neg A \mid X)} \cdot \frac{\Pr(\neg D \mid A, X)}{\Pr(\neg D \mid \neg A, X)} $$
In the above equation,
- \(X\) stands for any relevant background information;
- \(A\) stands for the hypothesis and \(\neg A\) stands for its negation (the statement that the hypothesis is false);
- \(D\) stands for a datum that is not observed;
- \(\Pr(A \mid X)\) means the probability of hypothesis \(A\) given only the background information \(X\), and similarly for the other expressions of the same form.
In the example of the cat, for the specific expected evidence of urine stains, we would have the following:
- \(A\) means “there is a cat living in my apartment.”
- \(\neg A\) means “there is not a cat living in my apartment.”
- \(D\) means “I find urine stains in the apartment.”
- \(\neg D\) means “I do not find urine stains in the apartment.”
- \(X\) might stand for background information such as “I have never brought a cat into the apartment.”
- \(\Pr(A \mid \neg D, X)\) means “the probability that there is a cat living in my apartment, given that I find no urine stains in the apartment and I have never brought a cat into the apartment.”
- \(\Pr(\neg A \mid \neg D, X)\) means “the probability that there is not a cat living in my apartment, given that I find no urine stains in the apartment and I have never brought a cat into the apartment.”
- The expression $$ \frac{\Pr(A \mid \neg D, X)}{\Pr(\neg A \mid \neg D, X)} $$ is the odds in favor of there being a cat living in my apartment, given that I find no urine stains and have never brought a cat into the apartment.
- \(\Pr(A \mid X)\) means “the probability that there is a cat living in my apartment, given that I have never brought a cat into the apartment”.
- \(\Pr(\neg A \mid X)\) means “the probability that there is not a cat living in my apartment, given that I have never brought a cat into the apartment”.
- The expression $$ \frac{\Pr(A \mid X)}{\Pr(\neg A \mid X)} $$ is the odds in favor of there being a cat living in my apartment, given only the information that I have never brought a cat into the apartment.
- \(\Pr(D \mid A, X)\) means “the probability that I find urine stains in my apartment, if there is a cat living in my apartment and I have never brought a cat into my apartment.”
- \(\Pr(D \mid \neg A,X\) means “the probability that I find urine stains in my apartment, if there is not a cat living in my apartment and I have never brought a cat into my apartment.”
- The expression $$ \frac{\Pr(\neg D \mid A, X)}{\Pr(\neg D \mid \neg A, X)} $$ is the likelihood ratio for the (lack of) evidence; that is, the ratio of (a) the probability that I find no urine stains if there is a cat living in my apartment, versus (b) the probability that I find no urine stains if there is not a cat living in my apartment.
The important point is that $$ \Pr(\neg D \mid A, X) < \Pr(\neg D \mid \neg A, X). $$ That is, it is more probable that I find no urine stains if there is no cat living in my apartment than it is to find no urine stains if there is a cat living in my apartment. The fact that I do not find urine stains in my apartment multiplies the initial odds in favor of there being a cat living in my apartment by a number less than one, thus decreasing those odds. Each additional piece of expected evidence that I do not find further decreases the odds.
Spiritual Witness
Many people base their religious beliefs on some sort of “spiritual witness”—an epiphany of some kind, a “burning in the bosom,” a feeling of peace, a strong positive feeling that comes over them. The “testimonies” that religious believers give can be quite moving, evoking a deep emotional response in even the most cynical of persons.
Now I ask my Mormon friends and family, are these feelings, these emotional responses, a reliable basis for discerning the truth? I would argue that they are not. Internal emotions and feelings may be useful data for understanding your own self, but they are not evidence about the external world. Least of all do they provide a reliable guide to questions of cosmology… and a belief in an omnipotent Creator is no less than a belief about the ultimate nature and origin of the cosmos itself.
Why would you expect mere feelings to reliably guide you to the truth about any aspect of the external world? Because other people told you that they could? What makes you think these people are correct? Because of warm feelings you have towards these people? Can you see the circular logic?
Let’s take a look at some “testimonies” I have pulled off of the web:
It is difficult to describe to someone who has never felt it how the Gospel can change and improve one’s life. But learning the Gospel changed me totally. I now have no doubt about our purpose in this world and that I am following the right path, I have a certainty I never knew before, and a peace that goes with it.
“No doubt.” “I have a certainty.” If a person were to use these words in any other context, lacking a scrap of evidence for their belief, we would call them delusional.
I still remember sitting alone, reading the Book of Mormon, looking for errors, and questioning. The more I read, the more I became convinced that this book could only have one source, God. I was reading about God’s mercy and His willingness to forgive any sin… and I began to weep. I cried from the depth of my soul. I cried for my past ignorance and in joy of finally finding the truth.
So… assuming that a God exists, how does this woman know what a book that comes from God reads like, in comparison to texts written by mere human beings? Is she such an expert in divine versus secular textual classification that she can discern without a doubt which is which? Oh, but the Spirit bore testimony to her, you say. And how can she, with any reliability, distinguish this hypothetical testimony of the Spirit from an emotional response caused by a desire to find absolution for past wrongs she may have committed?
“What am I doing here?” Dear God. I am here because I believe in you, because I believe in the compelling and majestic words of the Book of Mormon, and because I believe in the Prophethood of your servant Joseph Smith. I know in my heart my decision is the right one. Please give me the courage to carry on with this new self and new life, that I may serve you well with a strong faith.
“I believe.” Based on what evidence? Warm fuzzy feelings? “I know in my heart.” Which is just a way of saying, “I want this to be true but I don’t actually know.”
I read the whole thing through in one sitting. I don’t think I even changed position…
As I read a thought began to form and then started going through my head over and over and over: “Oh my God! This is from God!” It was like being slammed in the head with a brick or a hard plank of wood. I was stunned. It was real… It was direct revelation— it really was the Word of God. Literally. Oh my God! This really IS from God!
A lot of thoughts form in my head. Some of them stay there for quite a long while. That, however, is not enough for me to conclude that the thought is correct.
Now, I know what my Mormon friends and family are thinking: I am hard-hearted and stiff-necked; I have shut myself off from the still, small voice of the Spirit. But I ask you to do some serious soul-searching of your own, and ask yourself: are these people really, truly justified in their belief, a belief that is unsupported by hard evidence but arises, by their own admission, from nothing more than a positive emotional response? Be honest with yourself. Don’t give the answer that you feel obligated to give. Don’t shy away from the answer that you fear to acknowledge, the answer that you fear would make you an unrighteous person.
Suppose now that these are the testimonies, not of LDS converts, but of converts to another religion altogether. Would you still agree that their belief is justified, based on the “spiritual witness” they have received? Perhaps I just substituted a few words here and there to make them look like LDS testimonies, say, changing “Islam” to “the Gospel,” “the Qur’an” to “the Book of Mormon,” and “Muhammed” to “Joseph Smith”. Does your answer change? Should it?