This post describes a Bayesian model I developed for my employer, The Modellers, a Hall & Partners company. The Modellers is a marketing research firm specializing in high-end analytics, and our parent company H & P does a lot of tracking studies; these are a series of surveys done at regular intervals to track how attitudes, awareness, and opinion about a company and its products change over time, or to track recognition of advertising campaigns. One problem one encounters is that sampling error always causes the numbers to fluctuate even when nothing is changing, which causes a certain amount of heartburn among clients. Anything to reduce the sampling noise is therefore worthwhile.
Some clients also want to run the surveys more frequently. The problem is that if you want to survey twice as frequently without increasing sampling noise, this requires twice the data collection costs — for example, surveying 1000 people every two weeks instead of 1000 people every four weeks.
But… if you just ran the survey two weeks ago, and two weeks before that, it’s not as if you have no idea what the results of the current survey are going to be. In most tracking studies you would be surprised to see large changes over a one-week or two-week period. So if you’re tracking, say, what proportion of a targeted population thinks your widget is the best on the market, the data from two weeks ago and four weeks ago provide some information about the population proportion today. It works the other way, too — the data you’ll collect two weeks and four weeks from now also have relevance to estimating the population proportion today, for the same reason that a large change is unlikely in that short of a time period. (That doesn’t help you today, but it can help you in a retrospective analysis.)
So, without further ado, here is an explanation of the model.
The Local Level Model
The local level model is one of the simplest forms of state-space model. It is used to track a real-valued quantity that cannot be precisely measured, but changes only a limited amount from one time step to the next.
For each time step \(t\geq0\) there is a real-valued state \(\alpha_{t}\) that cannot be directly observed, and a measurement variable \(y_{t}\) that constitutes a noisy measurement of \(\alpha_{t}\). There are two variance parameters:
- \(\sigma_{y}^{2}\) is the error variance that relates a noisy measurement \(y_{t}\) to the state \(\alpha_{t}\);
- \(\sigma_{\alpha}^{2}\) is is a “drift” variance that characterizes the typical magnitude of change in the state variable from one time step to the next.
Given \(\alpha_{0}\), \(\sigma_{y}\), and \(\sigma_{\alpha}\), the joint distribution for \(y_{0},\ldots,y_{T}\) and \(\alpha_{1},\ldots,\alpha_{T}\)
is given by
\begin{align}
\alpha_{t+1} & \sim\mathrm{Normal}\left(\alpha_{t},\sigma_{\alpha}\right)\nonumber \\
y_{t} & \sim\mathrm{Normal}\left(\alpha_{t},\sigma_{y}\right)\tag{1}\label{eq:llm0}
\end{align}
That is, the sequence of states \(\alpha_{0},\ldots,\alpha_{T}\) is a Gaussian random walk, and \(y_{t}\) is just \(\alpha_{t}\) with Gaussian noise added. If \(\sigma_{\alpha}\) were infinite, then \(y_{t}\) would be the only measurement providing information about \(\alpha_{t}\); but a finite \(\sigma_{\alpha}\) limits how much \(\alpha_{t}\) and \(\alpha_{t+1}\) may plausibly differ, hence \(y_{t-j}\) and \(y_{t+j}\) for \(j\neq 0\) also provide information about \(\alpha_{t}\). The information \(y_{t+j}\) provides about \(\alpha_{t}\) decreases as \(j\) or \(\sigma_{\alpha}\) increases.
Figure 1 shows the dependency graph for the local level model, for four time steps. Each node represents a variable in the model. An arrow from one variable to another indicates that the probability distribution for the second variable is defined conditional on the first. Comparing equations (\ref{eq:llm0}) to Figure 1, we see that the distribution for \(\alpha_{t+1}\) is conditional on \(\alpha_{t}\) and \(\sigma_{\alpha}\), hence there is an arrow from \(\alpha_{t}\) to \(\alpha_{t+1}\) and another arrow from \(\sigma_{\alpha}\) to \(\alpha_{t+1}\) in the dependency graph.

Figure 1: Dependency graph for 4 time steps of the local level model.
A Modified Local Level Model for Binomial Data
Now consider tracking the proportion of a population that would respond positively to a given survey question (if asked). Can we model the evolution of this proportion over time using the local level model? The proportion \(p_{t}\) at time \(t\) is not an arbitrary real value as in the local level model, but that is easily dealt with by defining the state variable to be \(\alpha_{t}=\mathrm{logit}\left(p_{t}\right)\), which ranges from \(-\infty\) to \(\infty\) as \(\alpha_{t}\) ranges from \(0\) to \(1\). The parameter \(\sigma_{\alpha}\) constrains what are plausible changes in the proportion from one time step to the next. But what of the real-valued measurement \(y_{t}\) and its error variance \(\sigma_{y}^{2}\)? We have instead a discrete measurement given by a number \(n_{t}\) of people surveyed at time \(t\) and a number \(k_{t}\) of positive responses at time \(t\). So for survey data we swap out the measurement model
\[
y_{t}\sim\mathrm{Normal}\left(\alpha_{t},\sigma_{y}\right)
\]
and replace it with a binomial measurement model:
\begin{align*}
k_{t} & \sim\mathrm{Binomial}\left(n_{t},p_{t}\right)\\
\mathrm{logit}\left(p_{t}\right) & =\alpha_{t}
\end{align*}
In the above, \(\mathrm{Binomial}\left(k\mid n,p\right)\) is the probability of getting \(k\) successes out of \(n\) independent trials, each having a probability \(p\) of success.
We end up with the following model: given \(\alpha_{0}\), \(\sigma\), and the sample sizes \(n_{t}\), the joint distribution for \(k_{0},\ldots,k_{T}\) and \(\alpha_{1},\ldots,\alpha_{T}\) is given by
\begin{align}
\alpha_{t+1} & \sim\mathrm{Normal}\left(\alpha_{t},\sigma\right)\nonumber \\
k_{t} & \sim\mathrm{Binomial}\left(n_{t},p_{t}\right)\nonumber \\
p_{t} & =\mathrm{logit}^{-1}\left(\alpha_{t}\right)\tag{2}\label{eq:llm-binomial}
\end{align}
where we have renamed \(\sigma_{\alpha}\) as just \(\sigma\), since it is the only variance parameter.
Figure 2 shows the dependency graph for this binomial local-level model. As before, the sequence of states \(\alpha_{0},\ldots,\alpha_{T}\) is a Gaussian random walk. As before, the fact that \(\sigma\) is finite means that, not only \(k_{t}\), but also \(k_{t-j}\) and \(k_{t+j}\) for \(j\neq0\) provide information about \(\alpha_{t}\), in decreasing amounts as \(j\) or \(\sigma\) increases.
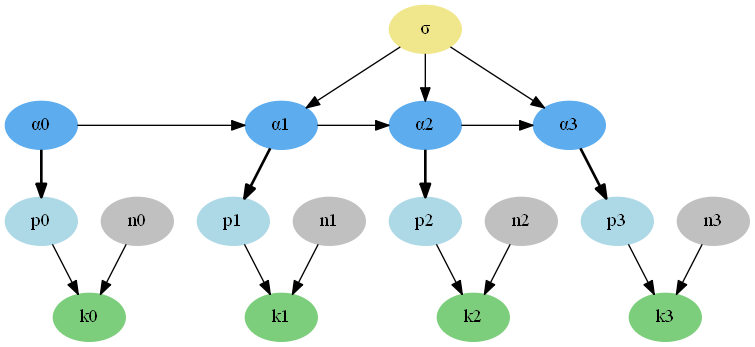
FIgure 2: Dependency graph for 4 time steps of the binomial local level model.
A Bayesian Perspective
The frequentist statistics that most researchers learn treats probabilities as long-run frequencies of events. Bayesian probabilities, in constrast, are epistemic probabilities (cox)(jaynes): they measure degrees of certainty in propositions.
The binomial local level model as we have presented it has two parameters whose values are unknown a priori: the drift variance \(\sigma^{2}\) and the initial state \(\alpha_{0}\). To have a complete Bayesian model we must define prior distributions over these variables. These prior distributions encode our background information on what are plausible values for the variables. We use
\begin{align}
\alpha_{0} & \sim\mathrm{Normal}\left(0,s_{\alpha}\right)\nonumber \\
\sigma & \sim\mathrm{HalfNormal}\left(s_{\sigma}\right)\tag{3}\label{eq:prior}
\end{align}
where \(\mathrm{HalfNormal}(s)\) is a normal distribution with standard deviation \(s\), truncated to allow only positive values. (See Figure 3.) If we choose \(s_{\alpha}=1.6\) then this results in a prior over \(p_{0}\) that is approximately uniform. Based on examination of data from past years, we might choose \(s_{\sigma}=0.105\sqrt{w}\), where \(w\) is the number of weeks in one time period. This allows plausible values for the drift standard deviation \(\sigma\) to range from 0 to \(0.21\sqrt{w}\). The high end of that range corresponds to a typical change over the course of a single month of around 10% absolute (e.g., an increase from 50% to 60%, or a decrease from 40% to 30%.)
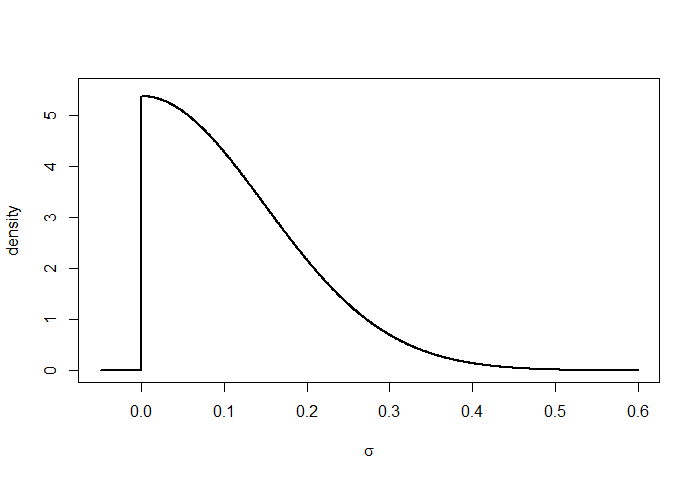
Figure 3: Probability density curve for HalfNormal(0.105 * sqrt(2)).
The model specification given by (\ref{eq:llm-binomial}) and (\ref{eq:prior}) is just a way of describing a joint probability distribution for the parameters \(\alpha_{0},\ldots,\alpha_{T}\), \(\sigma\), and data \(k_{0},\ldots,k_{T}\), given the sample sizes \(n_{0},\ldots,n_{T}\); this joint distribution has the following density function \(g\):
\begin{multline*}
g\left(\sigma,\alpha_{0},k_{0},\ldots,\alpha_{T},k_{T}\mid n_{0},\ldots,n_{T}\right)=\\
f_{1}\left(\sigma\right)g_{2}\left(\alpha_{0}\right)f_{3}\left(k_{0}\mid n_{0},\mathrm{logit}^{-1}\left(\alpha_{0}\right)\right) \\ \cdot\prod_{t=1}^{T}g_{4}\left(\alpha_{t}\mid\alpha_{t-1},\sigma\right)f_{3}\left(k_{t}\mid n_{t},\mathrm{logit}^{-1}\left(\alpha_{t}\right)\right)
\end{multline*}
where
\begin{align*}
f_{1}\left(\sigma\right) & =\mathrm{HalfNormal}\left(\sigma;s_{\sigma}\right)\\
g_{2}\left(\alpha\right) & =\mathrm{Normal}\left(\alpha;0,s_{\alpha}\right)\\
f_{3}\left(k\mid n,p\right) & =\mathrm{Binomial}\left(k;n,p\right)\\
g_{4}\left(\alpha_{t}\mid\alpha_{t-1},\sigma\right) & =\mathrm{Normal}\left(\alpha_{t};\alpha_{t-1},\sigma\right)\\
\mathrm{HalfNormal}\left(x;s\right) & =\begin{cases}
\frac{2}{\sqrt{2\pi}s}\exp\left(-\frac{x^{2}}{2s^{2}}\right) & \mbox{if }x > 0\\
0 & \mbox{otherwise}
\end{cases}\\
\mathrm{Normal}\left(x;\mu,s\right) & =\frac{1}{\sqrt{2\pi}s}\exp\left(-\frac{\left(x-\mu\right)^{2}}{2s^{2}}\right)\\
\mathrm{Binomial}\left(k;n,p\right) & =\frac{n!}{k!(n-k)!}p^{k}\left(1-p\right)^{n-k}
\end{align*}
This formula for the joint density is just the product of the (conditional) densities for the individual variables.
Alternatively, we can express the model directly in terms of the proportions \(p_{t}\) instead of their logits \(\alpha_{t}\); using the usual change-of-variables formula, the joint distribution for \(p_{0},\ldots,p_{T}\), \(\sigma\), and \(k_{0},\ldots,k_{T}\) conditional on \(n_{0},\ldots,n_{T}\) then has the following density function \(f\):
\begin{multline*}
f\left(\sigma,p_{0},k_{0}.\ldots,p_{T},k_{T}\mid n_{0},\ldots,n_{T}\right)=\\
f_{1}\left(\sigma\right)f_{2}\left(p_{0}\right)f_{3}\left(k_{0}\mid n_{0},p_{0}\right)\cdot\prod_{t=1}^{T}f_{4}\left(p_{t}\mid p_{t-1},\sigma\right)f_{3}\left(k_{t}\mid n_{t},p_{t}\right)
\end{multline*}
where
\begin{align*}
f_{2}\left(p\right) & =p^{-1}\left(1-p\right)^{-1}\mathrm{Normal}\left(\mathrm{logit}\left(p\right);0,s_{\alpha}\right)\\
f_{4}\left(p_{t}\mid p_{t-1},\sigma\right) & =p_{t}^{-1}\left(1-p_{t}\right)^{-1}\mathrm{Normal}\left(\mathrm{logit}\left(p_{t}\right);\mathrm{logit}\left(p_{t-1}\right),\sigma\right).
\end{align*}
For a Bayesian model there is no need to continue on and define estimators and test statistics, investigate their sampling distributions, etc. The joint distribution for the model variables, plus the rules of probability theory, are all the mathematical apparatus we need for inference. To make inferences about an unobserved model variable \(X\) after collecting the data that observable variables \(Y_{1},\ldots,Y_{n}\) have values \(y_{1},\ldots,y_{n}\) respectively, we simply apply the rules of probability theory to obtain the distribution for \(X\) conditional on \(Y_{1}=y_{1},\ldots,Y_{n}=y_{n}\).
For example, if we are interested in \(p_{T}\), then (conceptually) the procedure for making inferences about \(p_{T}\) given the survey counts \(k_{0},\ldots,k_{T}\) and sample sizes \(n_{0},\ldots,n_{T}\) is this:
- Marginalize (sum/integrate out) the variables we’re not interested in, to get a joint probability density function for \(p_{T}\) and the data variables \(k_{0},\ldots,k_{T}\):
\[
\begin{array}{l}
f\left(p_{T},k_{0},\ldots,k_{T}\mid n_{0},\ldots,n_{T}\right)=\\\
\qquad\int_{0}^{\infty}\int_{0}^{1}\cdots\int_{0}^{1}f\left(\sigma,p_{0},k_{0},\ldots,p_{T},k_{T}\mid n_{0},\ldots,n_{T}\right)\,\mathrm{d}p_{0}\cdots\mathrm{d}p_{T-1}\,\mathrm{d}\sigma.
\end{array}
\]
This is just a variant of the rule from probability theory that says that
\[
\Pr\left(A\right)=\Pr\left(B_{1}\right)+\cdots+\Pr\left(B_{m}\right)
\]
when \(A\) is equivalent to “\(B_{1}\) or … or \(B_{m}\)” and \(B_{1},\ldots,B_{m}\) are mutually exclusive propositions (no overlap). - Compute the conditional density function (also known as the posterior density function):
\[
f\left(p_{T}\mid k_{0},n_{0},\ldots,k_{T},n_{T}\right)=\frac{f\left(p_{T},k_{0},\ldots,k_{T}\mid n_{0},\ldots,n_{T}\right)}{\int_{0}^{1}f\left(p_{T},k_{0},\ldots,k_{T}\mid n_{0},\ldots,n_{T}\right)\,\mathrm{d}p_{T}}.
\]
This is just a variant of the rule for conditional probabilities,
\[
\Pr\left(A_{i}\mid C,D\right)=\frac{\Pr\left(A_{i}\mbox{ and }C\mid D\right)}{\Pr(C\mid D)},
\]
combined with the rule that, if it is known that exactly one of \(A_{1},\ldots,A_{m}\) is true, then
\[
\Pr(C)=\Pr\left(A_{1}\mbox{ and }C\right)+\cdots+\Pr\left(A_{m}\mbox{ and }C\right).
\] - Given any bounds \(a < b\), we can now compute the probability that \(a\leq p_{T}\leq b\), conditional on the data values \(k_{0},\ldots,k_{T}\):
$$
\Pr\left(a\leq p_{T}\leq b\mid k_{0},\ldots,k_{T},n_{0},\ldots,n_{T}\right)=\int_{a}^{b}f\left(p_{T}\mid k_{0},n_{0},\ldots,k_{T},n_{T}\right)\,\mathrm{d}p_{T}
$$This is known as a posterior probability, as it is the probability we obtain after seeing the data. In this step we get the posterior probability of \(a\leq p_{T}\leq b\) by, roughly, just summing over all the possible values of \(p_{T}\) between \(a\) and \(b\).
We can make inferences about \(\Delta_{T}=p_{T}-p_{0}\) in a similar fashion, using the joint density function for \(\sigma,p_{0},k_{0},\ldots,p_{T-1},k_{T-1},\Delta_{T},k_{T}\):
\[
\begin{array}{l}
h\left(\sigma,p_{0},k_{0},\ldots,p_{T-1},k_{T-1},\Delta_{T},k_{T}\mid n_{0},\ldots,n_{T}\right)=\\
\qquad f\left(\sigma,p_{0},k_{0},\ldots,p_{T-1},k_{T-1},p_{0}+\Delta_{T},k_{T}\mid n_{0},\ldots,n_{T}\right).
\end{array}
\]
In practice, computing all these high-dimensional integrals exactly is usually intractably difficult, which is why we resort to Markov chain Monte Carlo methods (mcmc). The actually computational procedure is then this:
- Draw a dependent random sample \(x_{1},\ldots,x_{m}\) from the joint conditional distribution
\[
f\left(\sigma,p_{0},\ldots,p_{T}\mid k_{0},n_{0},\ldots,k_{T},n_{T}\right)
\]
using Markov chain Monte Carlo. Each of the sample values is an entire vector \(\left(\sigma,p_{0},\ldots,p_{T}\right)\). - Approximate the posterior distribution for the quantity of interest as a histogram of values computed from the sample values \(x_{i}\), where \(x_{i}=\left(\sigma^{(i)},p_{0}^{(i)},\ldots,p_{t}^{(i)}\right)\). For example, if we’re just interested in \(p_{T}\), then for each \(x_{i}\) we create a histogram from the values \(p_{T}^{(i)}\), \(1\leq i\leq m\). If we’re interested in \(p_{T}-p_{0}\), then we create a histogram from the values \(\Delta^{(i)}=p_{T}^{(i)}-p_{0}^{(i)}\), \(1\leq i\leq m\).
A Graphical Example
In order to get an intuition for how this model works, it is helpful to see how the inferred posterior distribution for \(p_{t}\) (the population proportion at time \(t\)) evolves as we add new data points. We have done this in Figure 4, assuming for simplicity that the drift variance \(\sigma^{2}\) is known to be \(0.15^{2}\). The first row correspdonds to \(t=0\), the second to \(t=1\), etc.

Figure 4
The left column displays
\[
f\left(p_{t}\mid\sigma,n_{0},k_{0},\ldots,n_{t-1},k_{t-1}\right),
\]
that is, the inferred probability density function for \(p_{t}\) given known values for \(\sigma\) and survey results up to the previous time step.
The middle column displays the likelihood
\[
\Pr\left(k_{t}\mid n_{t},p_{t}\right)=\frac{n_{t}!}{k_{t}!\left(n_{t}-k_{t}\right)!}p_{t}^{k_{t}}\left(1-p_{t}\right)^{k_{t}},
\]
which is the information provided by the survey results from time period \(t\).
The right column displays
\[
f\left(p_{t}\mid\sigma,n_{0},k_{0},\ldots,n_{t-1},k_{t-1}\right),
\]
that is, the inferred probability density for \(p_{t}\) given known values for \(\sigma\) and survey results up to and including time step \(t\).
Here are some things to note about Figure 4:
- Each density curve in the right column is obtained by taking the density curve in the left column, multiplying by the likelihood curve, and rescaling the result so that the area under the density curve is 1. That is,
$$
f\left(p_{t}\mid\sigma,n_{0},k_{0},\ldots,n_{t-1},k_{t-1}\right)
$$
acts like a prior distribution for \(p_{t}\), which is updated by the new data \(n_{t},k_{t}\) to obtain a posterior distribution
$$
f\left(p_{t}\mid\sigma,n_{0},k_{0},\ldots,n_{t-1},k_{t-1},n_{t},k_{t}\right).
$$
In the right column this prior is shown in gray for comparison. - The density curves in the right column are narrower than the corresponding likelihood curves in the middle column. This increase in precision is what we gain from the informative prior in the left column.
- Except for row 0, each density curve in the left column is obtained by taking the density curve in the right column from the previous row (time step)—\(f\left(p_{t-1}\mid\cdots\right)\)—and making it a bit wider. (This necessarily lowers the peak of the curve, as the area under the curve must still be 1.) To understand this, recall that the left column is the inferred posterior for \(p_{t}\) given only the data up to the previous time step \(t-1\). Then all we know about \(p_{t}\) is whatever we know about \(p_{t-1}\), plus the fact that \(\mathrm{logit}\left(p_{t}\right)\) differs from \(\mathrm{logit}\left(p_{t-1}\right)\) by an amount that has a variance of \(\sigma^{2}\):
$$
\alpha_{t}\sim\mathrm{Normal}\left(\alpha_{t-1},\sigma\right)
$$
The density curve \(f(p_{t-1}\mid\cdots)\) is shown in gray in the left column for comparison.
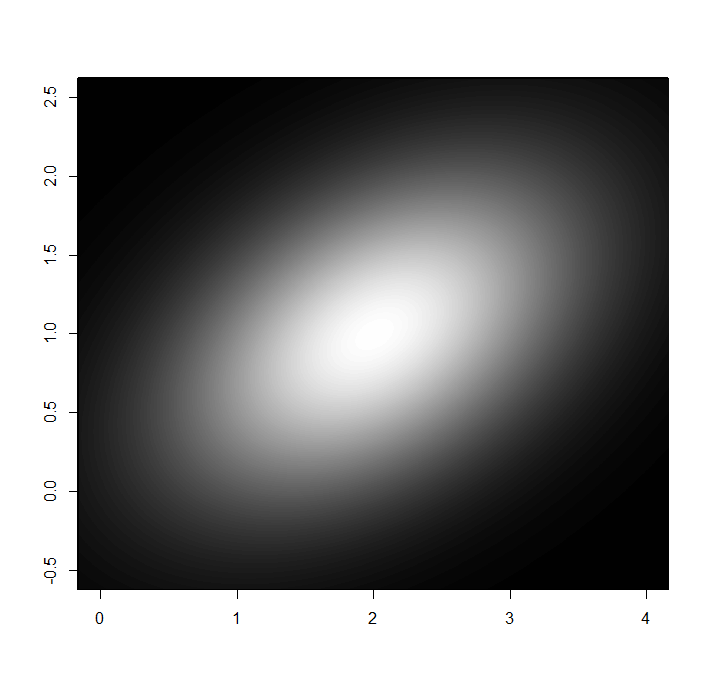
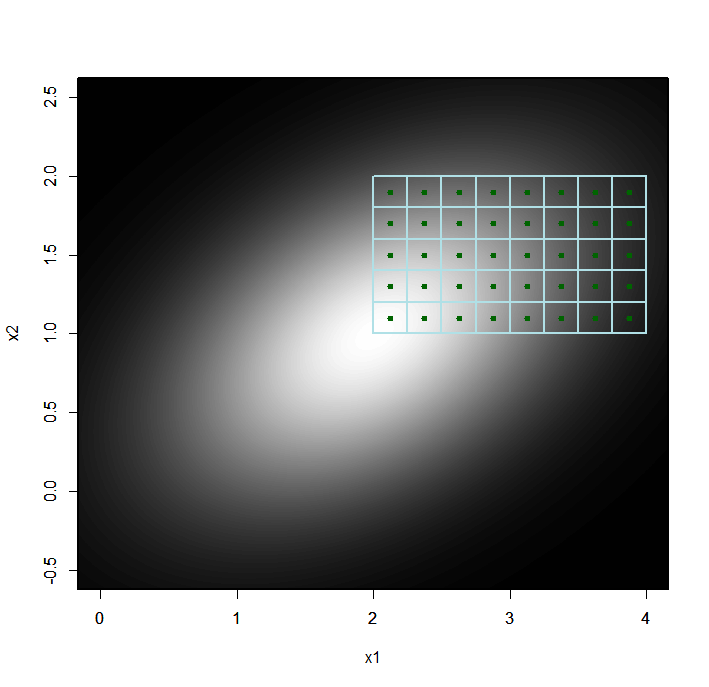
Of course, in reality we don’t know \(\sigma\) and must infer it instead. Figure 5 repeats the analysis of Figure 4, except that each plot shows a joint probability distribution for \(\sigma\) and \(p_{t}\).
- The left column is \(f\left(p_{t},\sigma\mid n_{0},k_{0},\ldots,n_{t-1},k_{t-1}\right)\).
- The middle column is the likelihood \(\Pr\left(k_{t}\mid n_{t},p_{t}\right)\).
- The right column is \(f\left(p_{t},\sigma\mid n_{0},k_{0},\ldots,n_{t},k_{t}\right)\).
- \(t\) increases from \(0\) to \(4\) from top to bottom.
- The \(y\) axis is \(\sigma\), the \(x\) axis is \(p_{t}\), and brighter shading indicates a higher probability density.
- The range for \(\sigma\) is \(0\) to \(0.45\).
Note the following:
- The “probability clouds” in the right column lean to the right. This is because the data indicate that \(p_{t}\) is increasing with \(t\) (note that the center of the likelihood moves to the right as \(t\) increases), but a near-zero value for \(\sigma\) doesn’t allow for much change in \(p_{t}\).
- As \(t\) increases we get more evidence for a nonzero value of \(\sigma\), and the “probabily clouds” move up away from the \(x\) axis.

Figure 5
A Computational Example
To help readers understand this model and the Bayesian concepts I’ve written an R script, binom-llm-comp-examp.R, that computes various posterior densities and posterior probabilities up to time step 3, exactly as described earlier. The script is intended to be read as well as run; hence the emphasis is on clarity rather than speed. In particular, since some functions compute integrals over upwards of four variables using a generic integration procedure, for each point in a density plot, some of the computations can take several minutes. Do not be daunted by the length of the script; it is long because half of it is comments, and little effort has been made to factor out common code as I judged it better to be explicit than brief. The script is grouped into blocks of short functions that are all minor variations of the same pattern; once you’ve read the first few in a block, you can skim over the rest.
Here are the steps to use the script:
- Save
binom-llm-comp-examp.Rto some folder. - Start up R.
- Issue the command
source('folder/binom-llm-comp-examp.R'),
replacingfolderwith the path to the folder where you savedbinom-llm-comp-examp.R. - Issue the command
demo(). This runs a demo showing the various commands the script provides. - Experiment with these commands, using different data values or intervals.
The following list describes the available commands. \(\Delta_{1}\) is \(p_{1}-p_{0}\), \(\Delta_{2}\) is \(p_{2}-p_{0}\), and \(\Delta_{3}\) is \(p_{3}-p_{0}\). In general, any time a command takes parameters \(k\) and \(n\), these are the survey data: \(k\) is a vector containing the count of positive responses for each time step, and \(n\) is a vector containing the sample size for each time step. Note that \(k[1]\) contains \(k_{0}\) (the count for time step 0), \(k[2]\) contains \(k_{1}\), etc., and similarly for \(n\).
-
print.config()Prints the values of various control parameters, prior parameters, and data values that you can modify. -
plot.p0.posterior.density(k,n)Plots the posterior density \(f\left(p_{0}\mid k_{0},n_{0}\right)\). -
p0.posterior.probability(a,b,k,n)Computes the posterior probability \(\Pr\left(a\leq p_{0}\leq b\mid k_{0},n_{0}\right)\). -
plot.p1.posterior.density(k,n)Plots the posterior density \(f\left(p_{1}\mid k_{0},n_{0},k_{1},n_{1}\right)\). -
p1.posteror.probability(a,b,k,n)Computes the posterior probability
$$
\Pr\left(a\leq p_{1}\leq b\mid k_{0},n_{0},k_{1},n_{1}\right).
$$ -
plot.delta1.posterior.density(k,n)Plots the posterior density
\(f\left(\Delta_{1}\mid k_{0},n_{0},k_{1},n_{1}\right)\). -
delta1.posterior.probability(a,b,k,n)Computes the posterior
probability
$$
\Pr\left(a\leq\Delta_{1}\leq b\mid k_{0},n_{0},k_{1},n_{1}\right).
$$ -
plot.p2.posterior.density(k,n)Plots the posterior density \(f\left(p_{2}\mid k_{0},n_{0},k_{1},n_{1},k_{2},n_{2}\right)\). -
p2.posteror.probability(a,b,k,n)Computes the posterior probability
$$
\Pr\left(a\leq p_{2}\leq b\mid k_{0},n_{0},k_{1},n_{1},k_{2},n_{2}\right).
$$ -
plot.delta2.posterior.density(k,n)Plots the posterior density
\(f\left(\Delta_{2}\mid k_{0},n_{0},k_{1},n_{1},k_{2},n_{2}\right)\). -
delta2.posterior.probability(a,b,k,n)Computes the posterior probability
$$
\Pr\left(a\leq\Delta_{2}\leq b\mid k_{0},n_{0},k_{1},n_{1},k_{2},n_{2}\right).
$$ -
plot.p3.posterior.density(k,n)Plots the posterior density \(f\left(p_{3}\mid k_{0},n_{0},k_{1},n_{1},k_{2},n_{2},k_{3},n_{3}\right)\). -
p3.posteror.probability(a,b,k,n)Computes the posterior probability
$$
\Pr\left(a\leq p_{3}\leq b\mid k_{0},n_{0},k_{1},n_{1},k_{2},n_{2},k_{3},n_{3}\right).
$$ -
plot.delta3.posterior.density(k,n)Plots the posterior density
\(f\left(\Delta_{3}\mid k_{0},n_{0},k_{1},n_{1},k_{2},n_{2},k_{3},n_{3}\right)\). -
delta3.posterior.probability(a,b,k,n)Computes the posterior probability
$$
\Pr\left(a\leq\Delta_{3}\leq b\mid k_{0},n_{0},k_{1},n_{1},k_{2},n_{2},k_{3},n_{3}\right).
$$References
[mcmc]Brooks, S., A. Gelman, G. Jones, and X.-L. Meng (2011). Handbook of Markov Chain Monte Carlo.
[cox]Cox, R. T. (1946). “Probability, frequency and reasonable expectation,” American Journal of Physics 17, 1–13.
[time-series]Durbin, J. and S. J. Koopman (2012). Time Series Analysis by State Space Methods, second edition.
[jaynes]Jaynes, E. T. (2003). Probability Theory: The Logic of Science.