(Part 1 is here.)
In part 1 I discussed choosing a sample size for the problem of inferring a proportion. Now, instead of a parameter estimation problem, let’s consider a hypothesis test.
This time we have two proportions \(\theta_0\) and \(\theta_1\), and two hypotheses that we want to compare: \(H_=\) is the hypothesis that \(\theta_0 = \theta_1\), and \(H_{\ne}\) is the hypothesis that \(\theta_0 \ne \theta_1\). For example, we might be comparing the effects of a certain medical treatment and a placebo, with \(\theta_0\) being the proportion of patients who would recover if given the placebo, and \(\theta_1\) being the proportion of patients who would recover if given the medical treatment.
To fully specify the two hypotheses we must define their priors for \(\theta_0\) and \(\theta_1\). For appropriate values \(\alpha > 0\) and \(\beta > 0\) let us define
- \(H_=\): \(\theta_0 \sim \mathrm{beta}(\alpha,\beta)\) and \(\theta_1 = \theta_0\).
- \(H_{\ne}\): \(\theta_0 \sim \mathrm{beta}(\alpha, \beta)\) and \(\theta_1 \sim \mathrm{beta}(\alpha, \beta)\) independently.
(\(\mathrm{beta}(\alpha,\beta)\) is a beta distribution over the interval \((0,1)\).) Our data are
- \(n_0\) and \(k_0\): the number of trials in population 0 and the number of positive outcomes among these trials.
- \(n_1\) and \(k_1\): the number of trials in population 1 and the number of positive outcomes among these trials.
We also define \(n = n_0 + n_1\) and \(k = k_0 + k_1\).
To get the likelihood of the data conditional only on the hypothesis \(H_=\) or \(H_{\ne}\) itself, without specifying a particular value for the parameters \(\theta_0\) or \(\theta_1\), we must “sum” (or rather, integrate) over all possible values of the parameters. This is called the marginal likelihood. In particular, the marginal likelihood of \(H_=\) is
\( \displaystyle \begin{aligned} & \Pr(k_0, k_1 \mid n_0, n_1, H_=) \\ = & \int_0^1 \mathrm{beta}(\theta \mid \alpha, \beta)\, \Pr\left(k_0 \mid n_0, \theta\right) \, \Pr\left(k_1 \mid n_0,\theta\right) \,\mathrm{d}\theta \\ = & c_0 c_1 \frac{\mathrm{B}(\alpha + k, \beta + n – k)}{\mathrm{B}(\alpha, \beta)} \end{aligned} \)
where \(\mathrm{B}\) is the beta function (not the beta distribution) and
\(\displaystyle \begin{aligned}c_0 & = \binom{n_0}{k_0} \\ c_1 & = \binom{n_1}{k_1} \\ \Pr\left(k_i\mid n_i,\theta\right) & = c_i \theta^{k_i} (1-\theta)^{n_i-k_i}. \end{aligned} \)
The marginal likelihood of \(H_{\ne}\) is
\( \displaystyle \begin{aligned} & \Pr\left(k_0, k_1 \mid n_0, n_1, H_{\ne}\right) \\ = & \int_0^1\mathrm{beta}\left(\theta_0 \mid \alpha, \beta \right)\, \Pr\left(k_0 \mid n_0, \theta_0 \right) \,\mathrm{d}\theta_0\cdot \\ & \int_0^1 \mathrm{beta}\left(\theta_1 \mid \alpha, \beta \right) \, \Pr\left(k_1 \mid n_1, \theta_1 \right)\,\mathrm{d}\theta_1 \\ = & c_0 \frac{\mathrm{B}\left(\alpha + k_0, \beta + n_0 – k_0\right)}{\mathrm{B}(\alpha, \beta)} \cdot c_1 \frac{\mathrm{B}\left(\alpha + k_1, \beta + n_1 – k_1\right)}{\mathrm{B}(\alpha, \beta)}. \end{aligned} \)
Writing \(\Pr\left(H_=\right)\) and \(\Pr\left(H_{\ne}\right)\) for the prior probabilities we assign to \(H_=\) and \(H_{\ne}\) respectively, Bayes’ rule tells us that the posterior odds for \(H_=\) versus \(H_{\ne}\) is
\(\displaystyle \begin{aligned}\frac{\Pr\left(H_= \mid n_0, k_0, n_1, k_1\right)}{ \Pr\left(H_{\ne} \mid n_0, k_0, n_1, k_1\right)} & = \frac{\Pr\left(H_=\right)}{\Pr\left(H_{\ne}\right)} \cdot \frac{\mathrm{B}(\alpha, \beta) \mathrm{B}(\alpha + k, \beta + n – k)}{ \mathrm{B}\left(\alpha + k_0, \beta + n_0 – k_0\right) \mathrm{B}\left(\alpha + k_1, \beta + n_1 – k_1\right)}. \end{aligned} \)
Defining \(\mathrm{prior.odds} = \Pr\left(H_{=}\right) / \Pr\left(H_{\ne}\right)\), the following R code computes the posterior odds:
post.odds <- function(prior.odds, α, β, n0, k0, n1, k1) {
n <- n0 + n1
k <- k0 + k1
exp(
log(prior.odds) +
lbeta(α, β) + lbeta(α + k, β + n - k) -
lbeta(α + k0, β + n0 - k0) - lbeta(α + k1, β + n1 - k1))
}
We want the posterior odds to be either very high or very low, corresponding to high confidence that \(H_=\) is true or high confidence that \(H_{\ne}\) is true, so let’s choose as our quality criterion the expected value of the smaller of the posterior odds and its inverse:
$$ E\left[\min\left(\mathrm{post.odds}\left(k_0,k_1\right), 1/\mathrm{post.odds}\left(k_0,k_1\right)\right) \mid n_0, n_1, \alpha, \beta \right] $$
where, for brevity, we have omitted the fixed arguments to \(\mathrm{post.odds}\). As before, this expectation is over the prior predictive distribution for \(k_0\) and \(k_1\).
In this case the prior predictive distribution does not have a simple closed form, and so we use a Monte Carlo procedure to approximate the expectation:
- For \(i\) ranging from \(1\) to \(N\),
- Draw \(h=0\) with probability \(\Pr\left(H_=\right)\) or \(h=1\) with probability \(\Pr\left(H_{\ne}\right)\).
- Draw \(\theta_0\) from the \(\mathrm{beta}(\alpha, \beta)\) distribution.
- If \(h=0\) then set \(\theta_1 = \theta_0\); otherwise draw \(\theta_1\) from the \(\mathrm{beta}(\alpha, \beta)\) distribution.
- Draw \(k_0\) from \(\mathrm{binomial}\left(n_0, \theta_0\right)\) and draw \(k_1\) from \(\mathrm{binomial}\left(n_1, \theta_1\right)\).
- Define \(z = \mathrm{post.odds}\left(k_0, k_1\right)\).
- Assign \(x_i = \min(z, 1/z)\).
- Return the average of the \(x_i\) values.
The following R code carries out this computation:
loss <- function(prior.odds, α, β, n0, k0, n1, k1) {
z <- post.odds(prior.odds, α, β, n0, k0, n1, k1);
pmin(z, 1/z)
}
expected.loss <- function(prior.odds, α, β, n0, n1) {
# prior.odds = P.eq / P.ne = (1 - P.ne) / P.ne = 1/P.ne - 1
# P.ne = 1 / (prior.odds + 1)
N <- 1000000
h <- rbinom(N, 1, 1 / (prior.odds + 1))
θ0 <- rbeta(N, α, β)
θ1 <- rbeta(N, α, β)
θ1[h == 0] <- θ0[h == 0]
k0 <- rbinom(N, n0, θ0)
k1 <- rbinom(N, n1, θ1)
x <- loss(prior.odds, α, β, n1, k1, n0, k0)
# Return the Monte Carlo estimate +/- error estimate
list(estimate=mean(x), delta=sd(x)*1.96/sqrt(N))
}
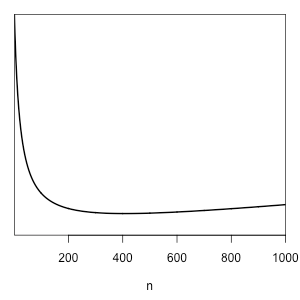
Suppose that \(H_=\) and \(H_{\ne}\) have equal prior probabilities, and \(\alpha=\beta=1\), that is, we have a uniform prior over \(\theta_0\) (and \(\theta_1\), if applicable). The following table shows the expected loss—the expected value of the minimum of the posterior odds against \(H_{\ne}\) and the posterior odds against \(H_=\)—as \(n_0 = n_1\) ranges from 200 to 1600:
| \(n_0\) | \(n_1\) | Expected loss |
|---|---|---|
| 200 | 200 | 0.130 |
| 400 | 400 | 0.095 |
| 600 | 600 | 0.078 |
| 800 | 800 | 0.069 |
| 1000 | 1000 | 0.062 |
| 1200 | 1200 | 0.057 |
| 1400 | 1400 | 0.053 |
| 1600 | 1600 | 0.050 |
We find that it takes 1600 trials from each population to achieve an expected posterior odds in favor of the (posterior) most probable results of 20 to 1.